Closing thoughts on A-Frame architecture
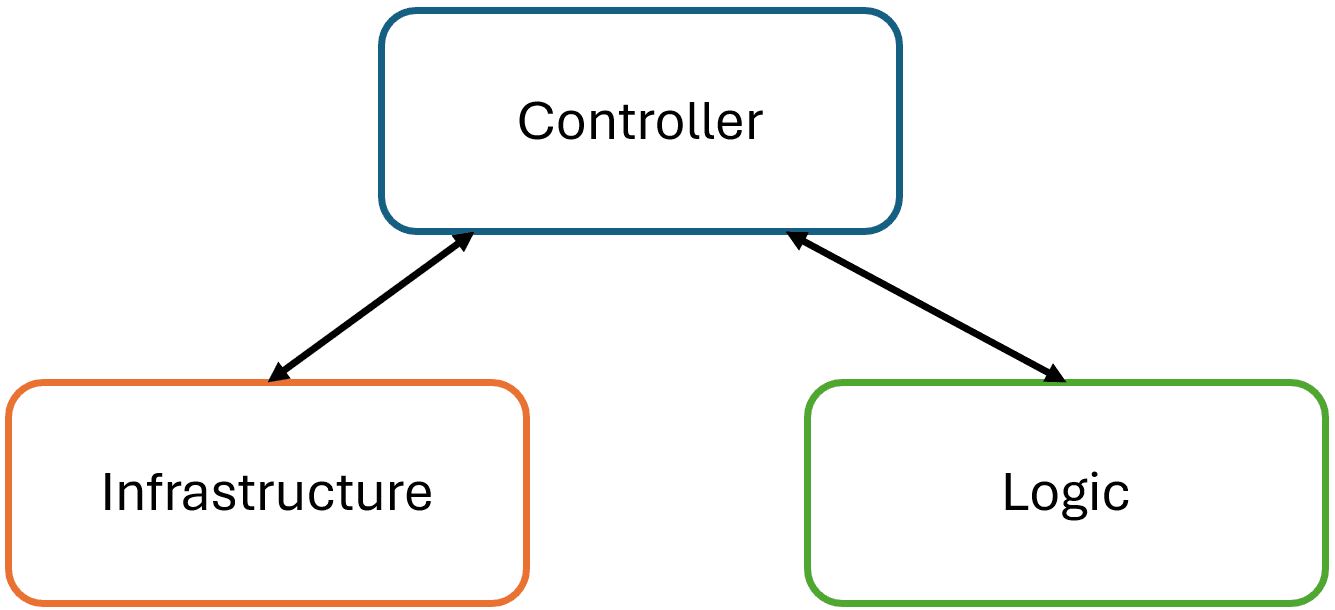
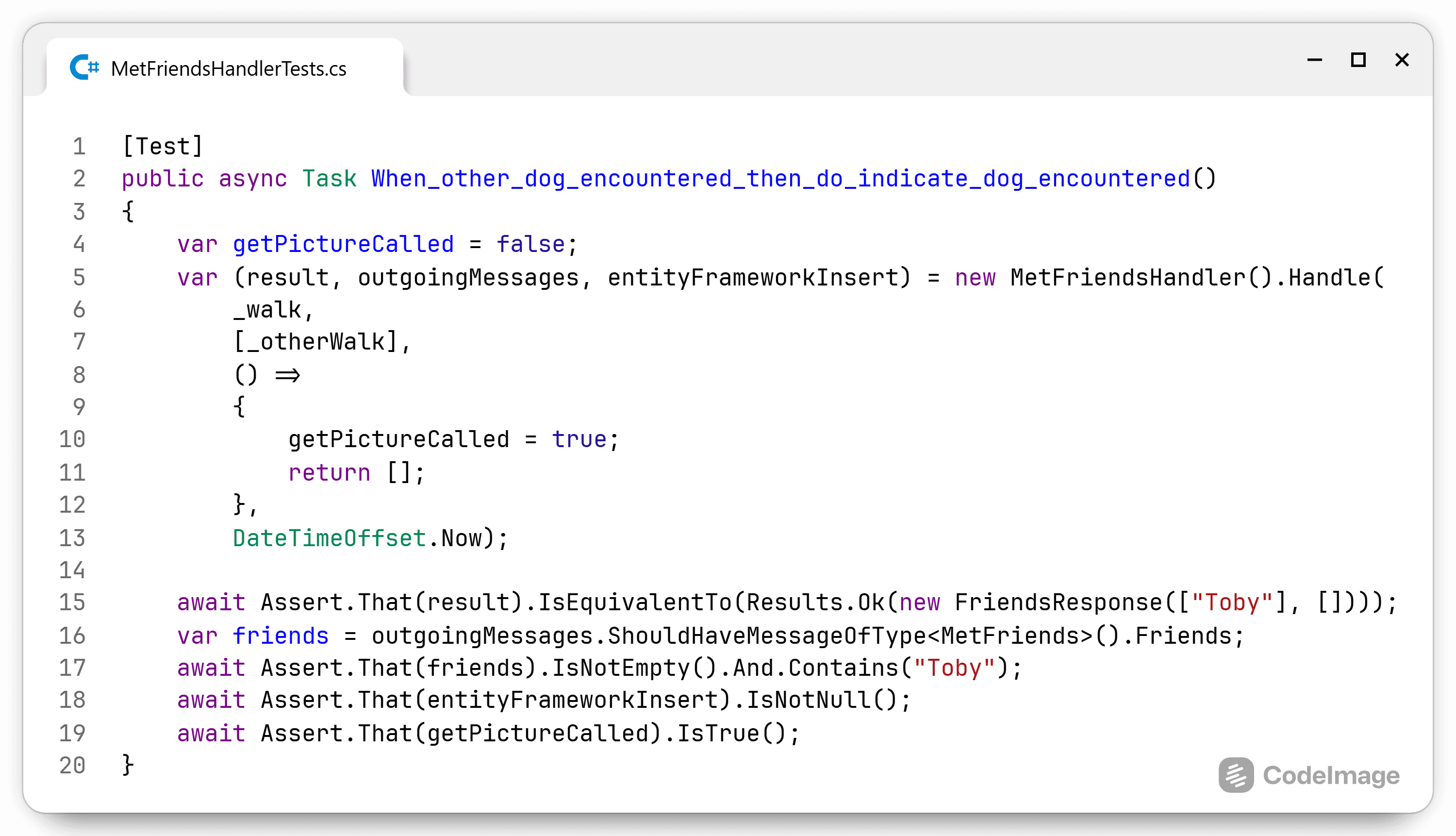
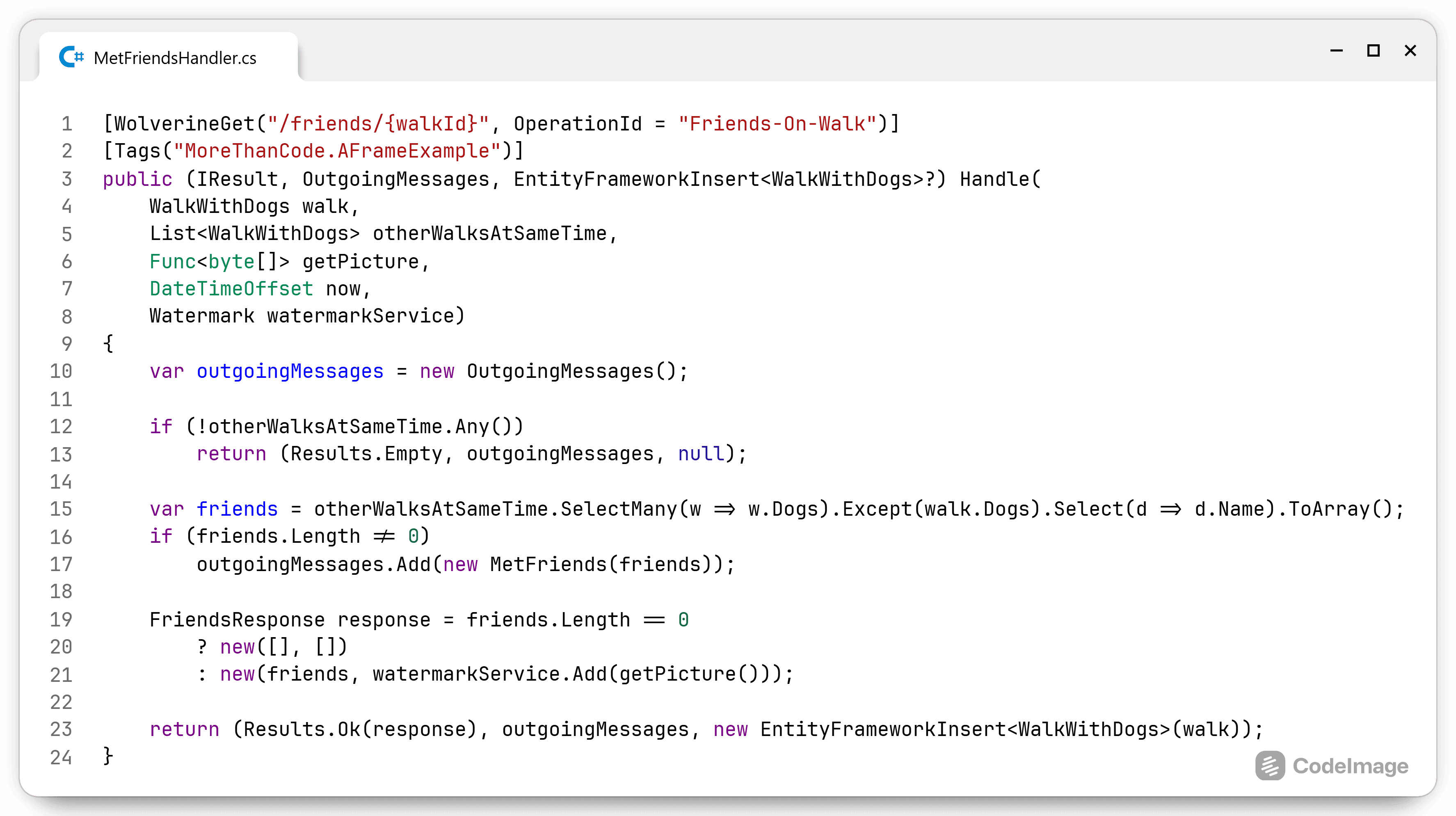
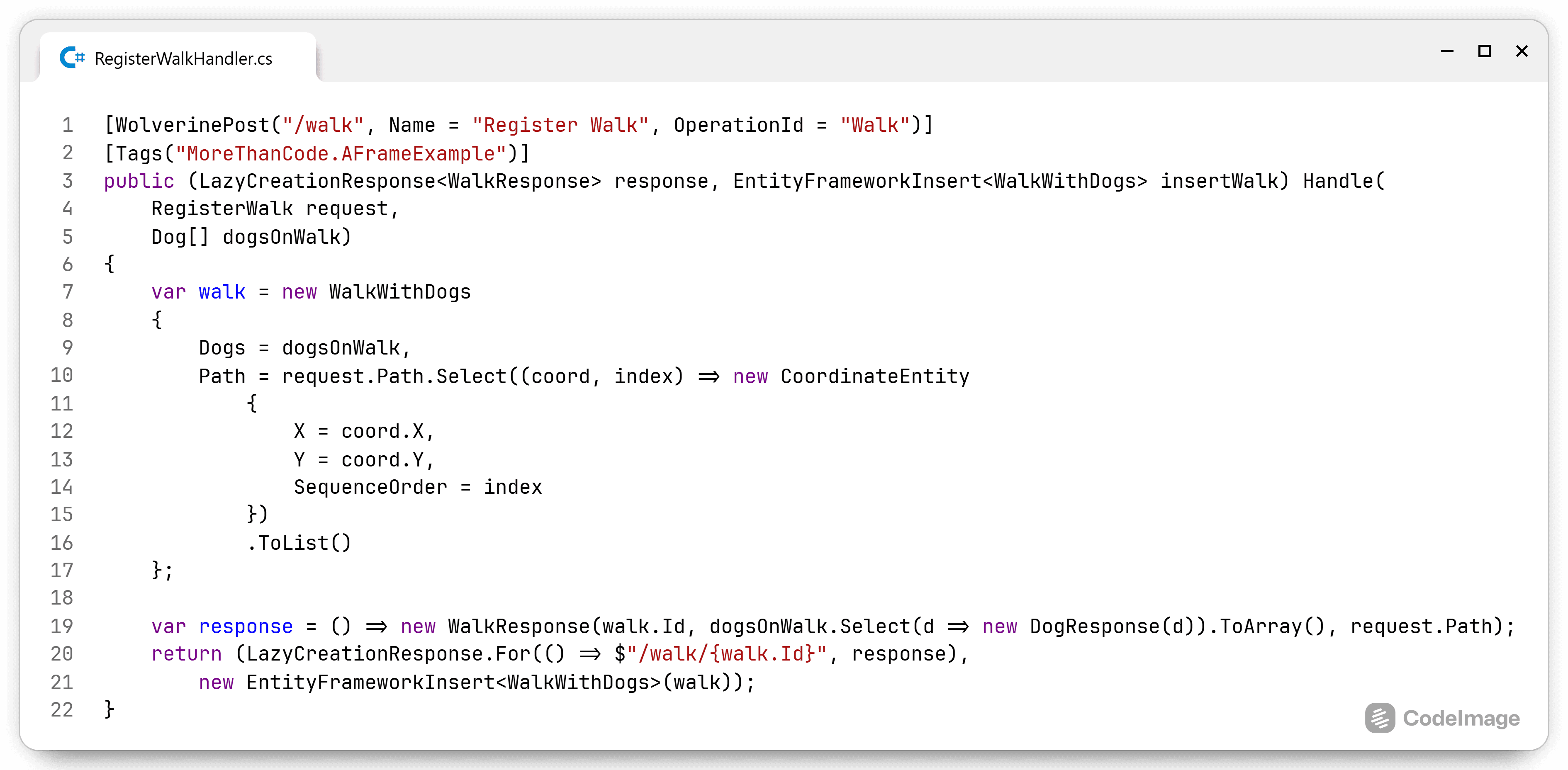
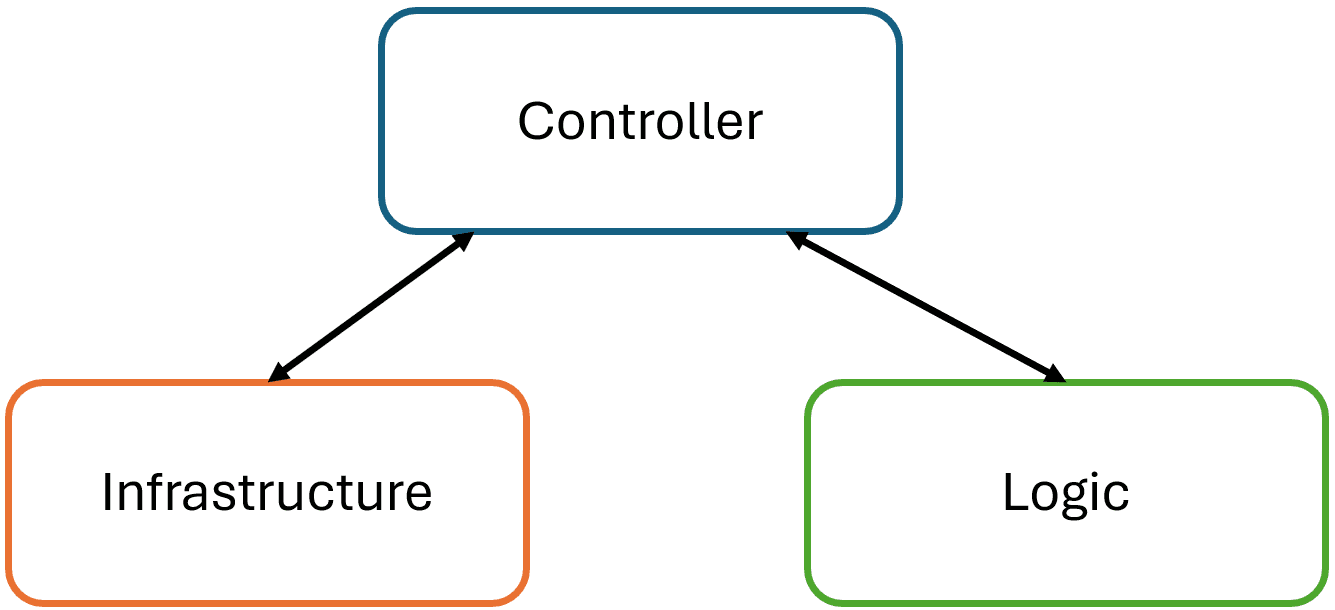
Phew, that was a lot. I'm always surprised how simple solutions contain so much detail and nuance when I try to explain them. I hope I conveyed the message that A-Frame simplifies code within a module or class by separating the infrastructure compone...
Aug 10, 20251 min read