It's been a while since I've blogged. Mainly because my life has been quite busy since my last post and I'm not sure if I'm picking up the habit as frequently as before. The reason I'm writing is that I responded to a Reddit post about using an automatic mapping tool and all the details I want to convey don't fit the format of a Reddit comment. The gist is that in the past few years, I've noticed that automatic mapping has quite some downsides, especially in the long run.
Now for a little disclaimer: I don't want to single out any specific automatic mapping framework; I dislike them all equally. So if any framework contributor recognizes themselves in my description, I'm not talking about you specifically. I don't dislike you personally, just the framework that you created. 😉
Why am I against automatic mapping? Well, there are three main reasons:
The syntax is not intuitive
High possibility for bugs
They do not save time
1. The syntax is not intuitive
Let's take a look at some mapping configurations. I'm just going to copy-paste from the examples that I find on the first few automatic mapping NuGets that I can find. Again, sorry for seemingly singling out specific frameworks; that is not my intention.
The most well-known is AutoMapper. Let's see how their projection works:
var configuration = new MapperConfiguration(cfg =>
cfg.CreateMap<CalendarEvent, CalendarEventForm>()
.ForMember(dest => dest.EventDate, opt => opt.MapFrom(src => src.Date.Date))
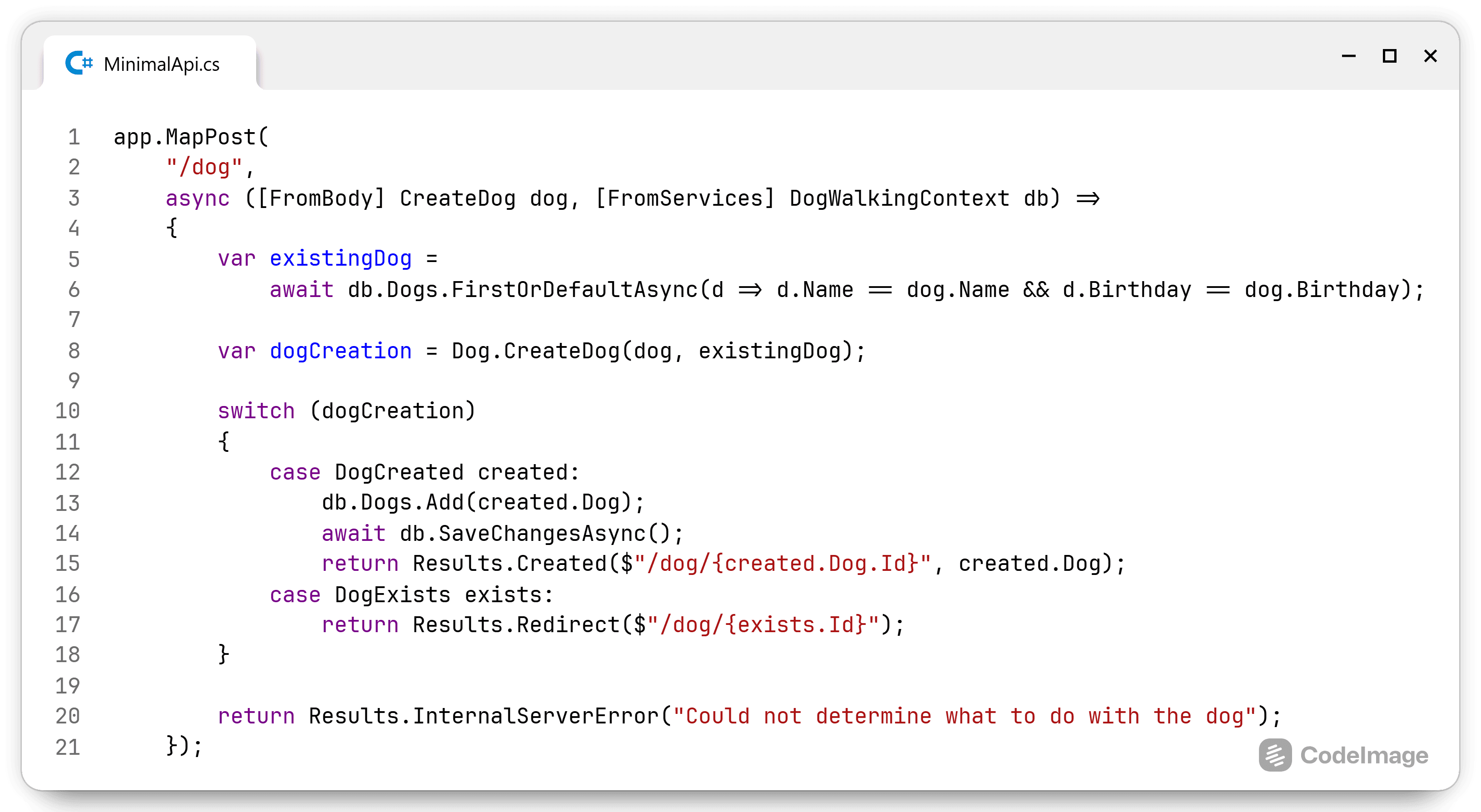
.ForMember(dest => dest.EventHour, opt => opt.MapFrom(src => src.Date.Hour))
.ForMember(dest => dest.EventMinute, opt => opt.MapFrom(src => src.Date.Minute)));
That is a lot of specifying what member goes where. I find this quite hard to follow. It's got a MapperConfiguration that takes a configuration function where we create a map with overrides for 3 specific members. It needs a lambda for selecting the source, then one which details what needs to be done with the output which in turn needs a lambda to select the data... I think this creates more functions than actual mapping code.
So let's look at another; Mapperly is mentioned in the Reddit post. According to their getting started guide, I need:
[Mapper(EnumMappingStrategy = EnumMappingStrategy.ByName)]
public static partial class CarMapper
{
[MapProperty(nameof(Car.Manufacturer), nameof(CarDto.Producer))]
public static partial CarDto MapCarToDto(Car car);
}
Okay, I need a partial class (because it generates the code so I can check that in, which is actually quite nice). I specify that enums need to be mapped by name instead of value. Which in and of itself is a quite compact way of describing what I want to do. My main problem here is that I need to use attributes to say how I want to do stuff. That's not going to be a lot of hassle wiring up all the different (computed) properties. /sarcasm Just in case anybody was doubting if I was serious or not.
Maybe TinyMapper can do better. Let's look at the example provided:
TinyMapper.Bind<Person, PersonDto>(config =>
{
config.Ignore(x => x.Id);
config.Ignore(x => x.Email);
config.Bind(source => source.LastName, target => target.Surname);
config.Bind(target => source.Emails, typeof(List<string>));
});
It requires less boilerplate than AutoMapper, but it's still a lot of boilerplate to specify special cases. In my experience (YMMV), most objects have at least one special case. Let's also focus on the Email property. It converts the emails to a list of string. Since it's specifying the destination type, I'm assuming the Emails property is not just a simple list of string on the source side. Why else specify the target type? I also hope somebody overwrote the .ToString() method so it returns the correct data of the emails. Otherwise, they'll just have a list of fully qualified namespaces instead of data.
So I find all of these examples not exactly readable or easy to understand. I also find that...
2. There's a high probability for bugs
The easiest example here is that you're trying to map two incompatible properties. Now that can happen in manual mapping as well, but in the case of Mapperly, I'll have to check the generated code. Ooh, I can't convert the person's name to their date of birth. Whoops, that crashed. Now in all fairness, this is an easy mistake to spot as most of the mapping frameworks use lambdas and they do check type compatibility. So I'll forgive them this one.
Not the more discreet one though: renaming things. Let's say I have a person class that I want to map to a DTO.
public class Person
{
public string FirstName { get; set; }
public string Name { get; set; }
}
public record PersonDto(string FirstName, string Name);
This scenario is very easily covered by all automatic mapping frameworks, both the ones listed above and others. After some time, there is a discussion about what the Name property of our model should be. Is it the full name or just the last name? With our handy refactoring tools, I can rename that ambiguous property in no time to LastName. A quick build and all looks fine. Until I run the software and see that I suddenly have no name in my JSON response anymore. Everything was fine, no build errors, all references wer. I mean, we all surely write automated tests for all our little mapping scenarios, right? Right! And that's not even taking into account I might add a computed property called Name that returns the concatenated FirstName and LastName.
This is not the first, nor the last, time I will see this type of bug appear because of automatic mapping. These bugs are very easy to slip into a codebase, especially by people who are not familiar with the code and all the usages of the properties. Even if you search for all places where the original Name property is used, it won't show up because most mapping frameworks don't spit that information out.
Helpful people of Reddit pointed out that Mapperly (and probably other frameworks that use source generators) don't have this problem as they create a file with the mapping inside. Our refactoring tools will find those references, they will show up in the usage of the property and compilation will throw errors when it's not updated. So point for Mapperly (and others who do it like this).
Another point they made is that Mapperly can be set to strict mode where all mappings must be addressed. This prevents me from creating a configuration where an unknown property cannot be mapped. This forces me to write more "easy to read" mapping configuration... but only if I remember to properly configure Mapperly.
Wait, maybe the redeeming quality is that...
3. They don't save time
A lot of the frameworks claim they will save you time and spare you the tedium of writing mapping out by hand. They forget to mention the learning curve of their framework. Looking up all the configuration, how it's best used, and what the limitations are can easily add up.
Couple that code is more read than written with deciphering the mapping syntax and any time they save is sucked right back up into other areas. You need to learn the framework, find bugs, run into limitations, ask ChatGPT to spit out the correct syntax, wondering why that one property just doesn't want to map correctly but the others do.
After summing it all up, I find that automatic mapping, whichever framework you choose, is not worth the hassle.
Then what is?
Plain, simple, boring, easy-to-read, and reliable handwritten mapping functions. In the person example, I would create this DTO:
record PersonDto(string FirstName, string LastName, string FullName)
{
internal static PersonDto From(Person person) =>
new(person.FirstName, person.LastName, $"{person.FirstName} {person.LastName}");
internal Person ToPerson() => new() { FirstName = FirstName, LastName = LastName };
}
The record ensures immutability so that I cannot change the DTO after I've created it. I have no problem adding mapping functions on the DTO so it knows how it's created or transforms back to a model. This saves me from having to create superfluous interfaces such as IPersonToDtoMapper or IMapPersonToDto, create an unnecessary implementation, forgo the wiring into the DI, and simplify where the mapping occurs because the interface is not injected and stored in a field. It's as simple as:
var people = new List<Person>();
people.Select(PersonDto.From);
var dtos = new List<PersonDto>();
dtos.Select(dto => dto.ToPerson());
This keeps the mapping logic near the edge of the application (endpoints, message queues, enterprise buses, file systems, HTTP calls,...), basically everywhere data leaves my control.
Quick shoutout to NyanArthur (and Hot-Profession4091 in a comment in this thread) for reminding me that I used the same technique they mention for mapping to and from DTOs: extension methods. I keep the extension methods near the DTOs as this is not domain knowledge, but mapping logic. This also ensures that the functions and data that change together exist together.
These days, I like to keep the mapping methods on the DTO, so the DTO knows how to transform itself into internal or external messages.
Complex scenarios
Not every mapping is this easy or straightforward and the created model needs to be valid. Increasing complexity of validation requires increasing complexity of the chosen solution.
💡
So start simple and add complexity only when it arises.
For example, the FirstName should not be empty. When validation needs to happen, I like to switch from simple constructors to a static Create method. Then return a specific validated object from the Create method. It can look like a Validated<Person> so any errors can be present on the Validated<> object.
I prefer this explicit object over implicit exceptions. This forces the calling code to handle all scenarios and keeps exceptions for exceptional scenarios. When it's possible that there is a failure scenario, then it should be apparent.
When the validation logic gets even more complex, my approach would depend on whether this validation needs to be shared across multiple features or if it is specific to this feature.
Avoid exposing domain models directly
In one of the comments, I read that they return the domain objects directly. I advise against doing this. A DTO is a view of the data you have, just like a page on a website or a XAML component is. The view contains all the data you want to expose, now and in the future. This allows me to change the internal model without affecting the view or contract to the outside world. In many cases, the internal model is different than the DTO.
When I'm experimenting with a feature, I do not want that new, unstable data to be exposed to the outside world. I want to be able to experiment with it, maybe deploy the data gathering part without making it available yet. The DTO allows me to have greater control over the contract that is available to my clients.
Testing
Since these are simple objects, I can quite easily create tests for them. Create a complex domain model and then map it to the different DTOs. Hint: snapshot testing with Verify is great for this scenario as it will fail when things don't map as planned.
No need to learn yet another framework, write unreadable bindings, and expose your software to subtle bugs all for the fallacy of saving time. Go forth and write boring code.