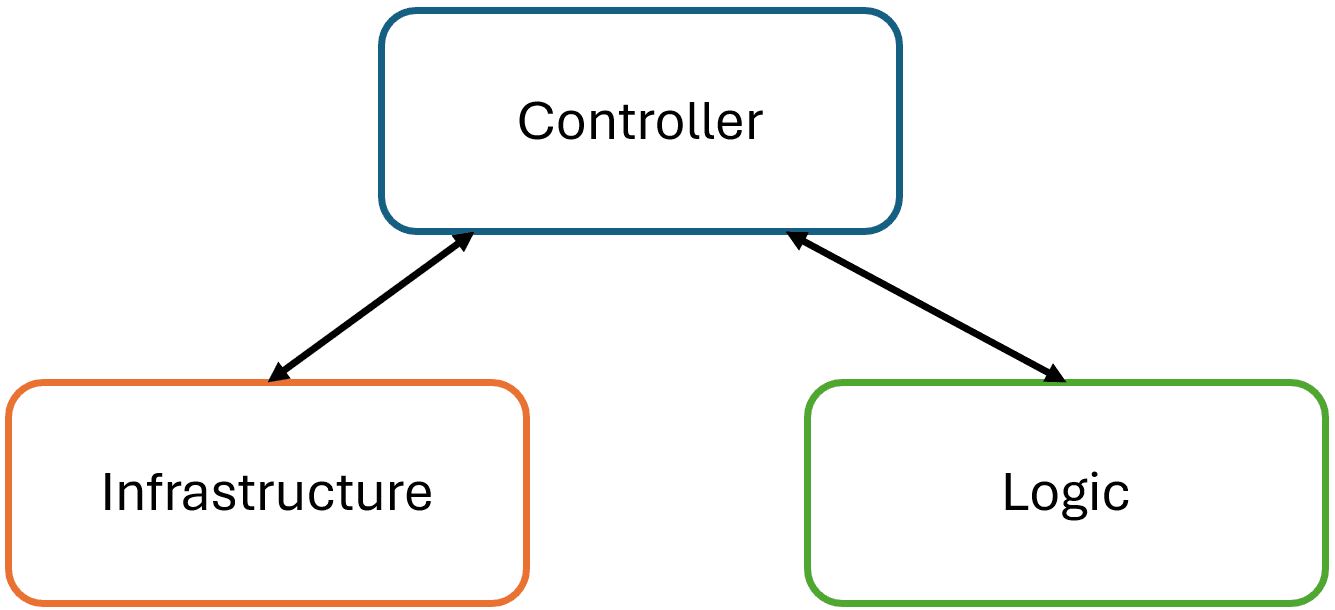
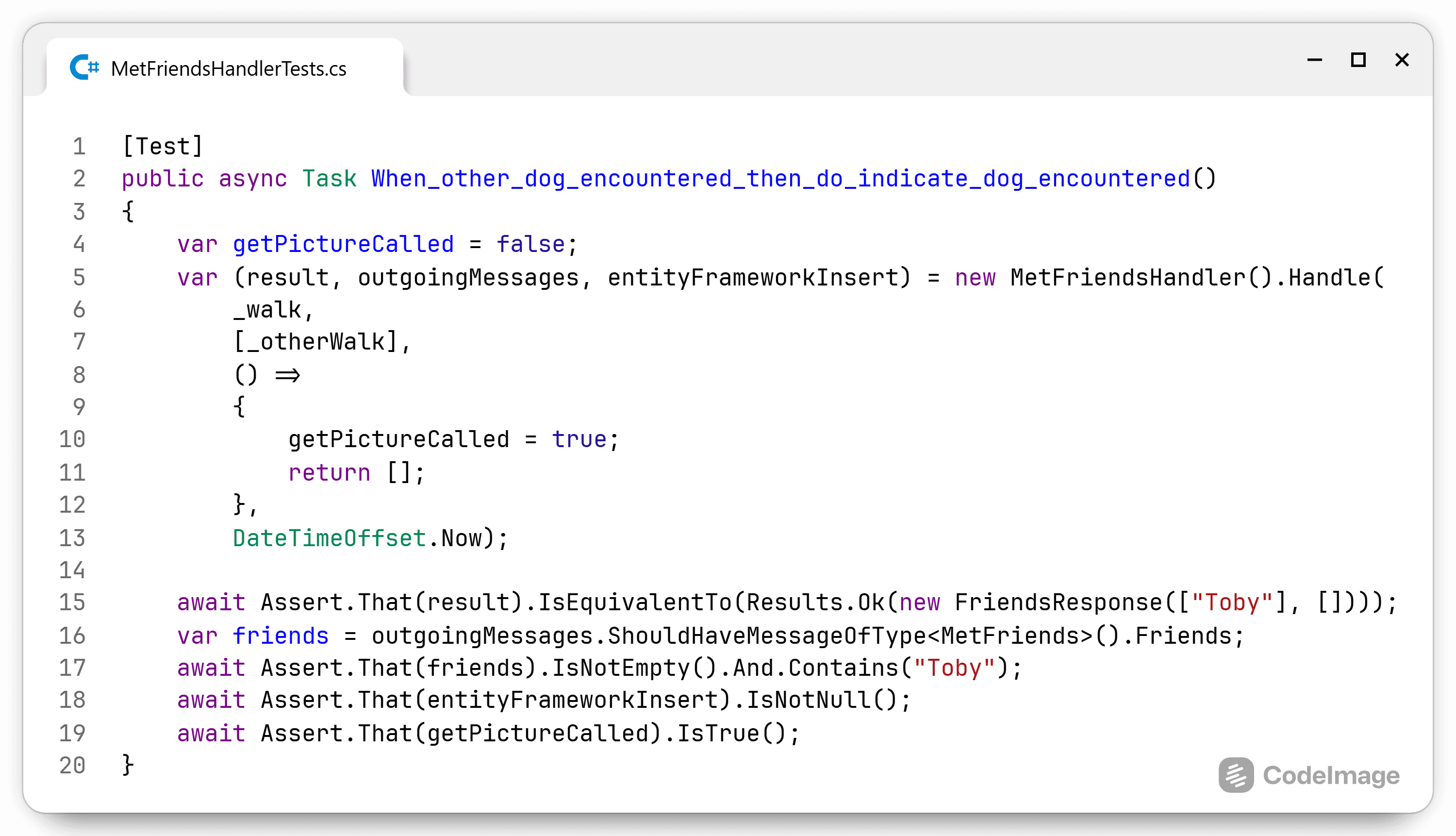
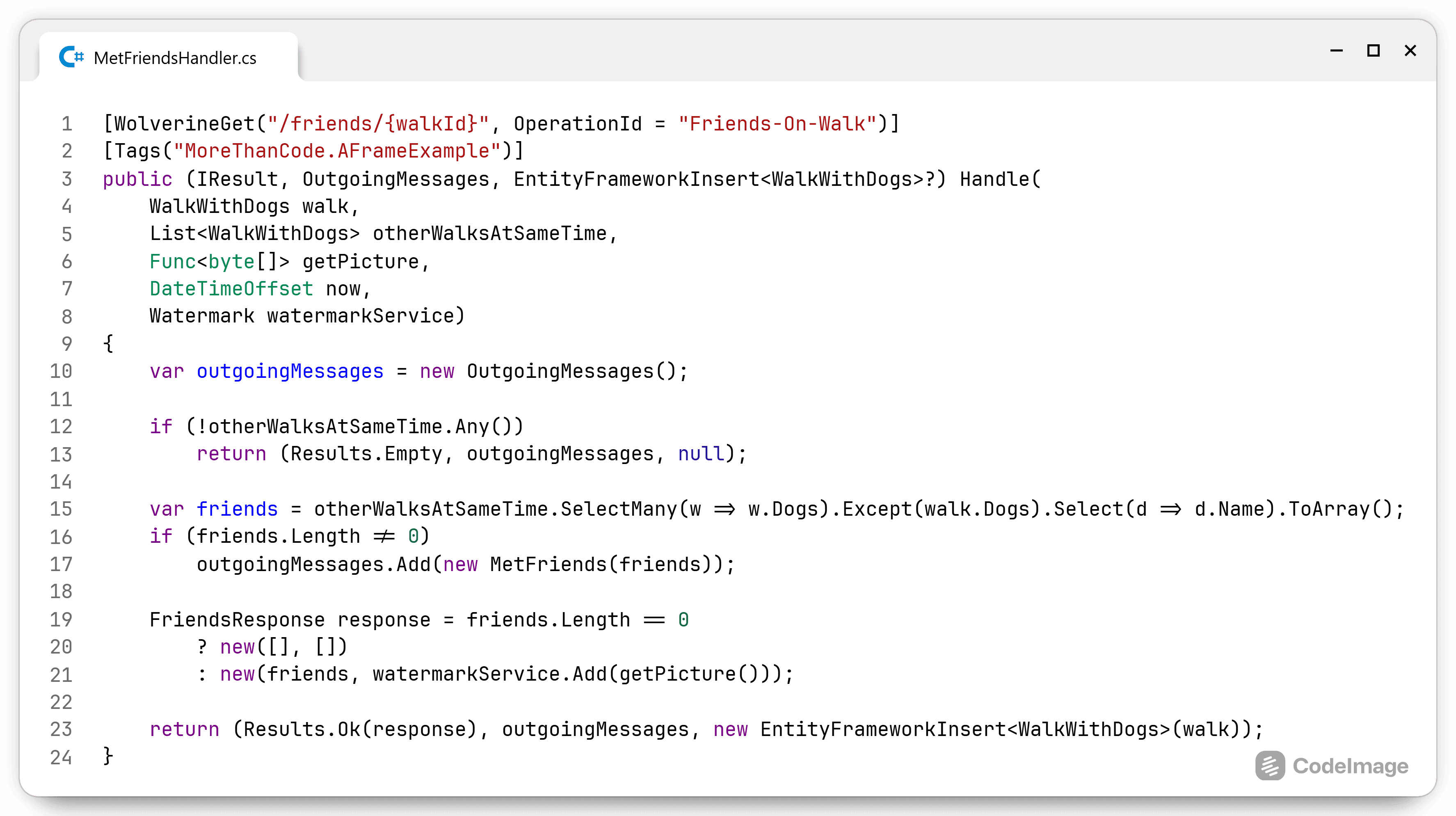
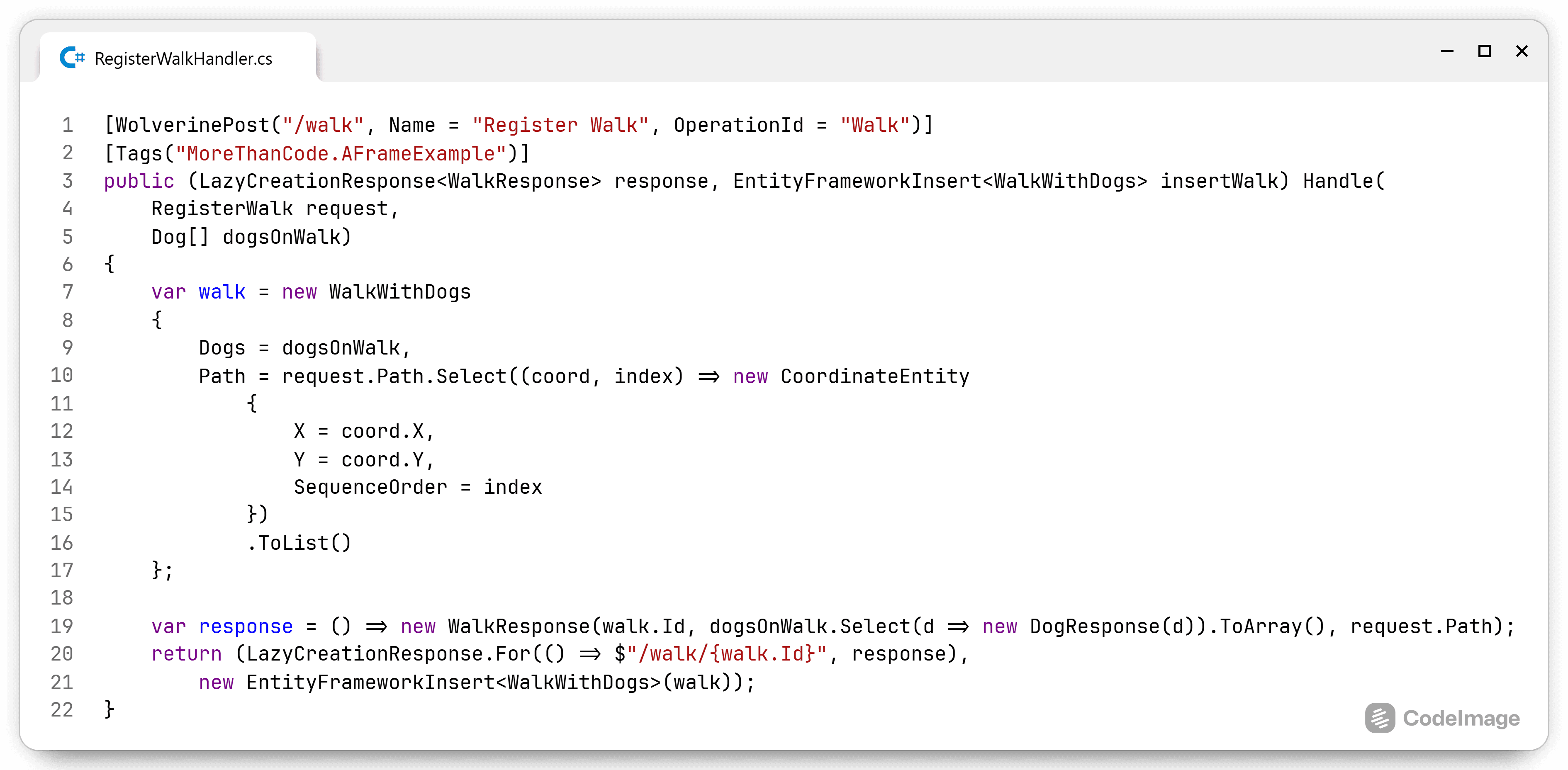
Trusting a codebase
Trust in a codebase can vary from module to module and is very fragile. I'll go into more detail of what I mean with trust and how to determine the level of trust you can have in a certain piece of code.
When I talk about trust, I mean that the code will do what it says it will do. I can trust code that does what it communicates. Trust is not whether good code practices have been used, SOLID-principles have been followed or any sort of architecture is in place. Trust is nothing more than being certain that an interface, class, method or variable will do what it says it will do without doing additional tasks.
Eventually, the level of trust, most of the time, correlates to how well good practices have been followed. Do not, however, make the mistake of thinking a high level of trust equals good code. Having trust is a sign of good code, but good code is more than just having trust that the methods do what they indicate. If the code doesn't do what the business needs or there is no easy way to extend the code, then I can have a high degree of trust in bad code.
A good first impression can set my level of trust very high but it will only take a few bad methods to shatter that trust. A bad first impression will set a low level of trust and will take a lot of good examples to improve the level of trust I have in a codebase.
An example of trustworthy code:
public void TryReserve(Seat seat)
{
var possibleReservation = _reservationRepository.LoadReservation(seat.Id);
if (possibleReservation != null)
{
throw new Exception("Seat already reserved.");
}
_reservationRepository.AddReservation(seat.Id);
}
// usage
var seat = GetCustomerSelectedSeat();
TryReserve(seat);
Notice that the names of the methods reveal what they do. The TryReserve method does not guarantee the reservation will be made. It can fail if the seat is already reserved. Also notice the GetCustomterSelectedSeat method in the usage section, this implies that it will fetch the seat selected by the customer and nothing else. Because the example of the TryReserve method doesn't do anything additional, I trust that the other method also doesn't do any unexpected tasks.
This is the effect of trust, but the GetCustomerSelectedSeat has additional indications that it can be trusted. The return value seat indicates that the method gets an object, so it does what it communicates. It contains domain terms such as "Seat". All these points increase the level of trust I have in this code.
When I start working with code and I don't know how well I can trust the codebase, I start looking at class, method and variable names and check that the implementation does what the name says. The name should be easy to understand and should clearly describe what the method should do. Each method I encounter that does what it says, increases the trust I have in the codebase.
Then I look for jargon and domain specific words. Trustworthy code will use the language of the business it supports. This will indicate that the developer(s) that worked on the code understand what they are creating.
Easy to understand unit tests where the assertion logic shows me that the code under test actually does what it should do is an immediate increase in trust. It does not rule out that the code is fully trustworthy, though. I can have a higher degree of trust in the tests than I have of the production code or vice versa. When less time is devoted to tests, then shortcuts can be taken and bad names chosen. Thus lowering the trust I have in the tests. The tests can then still be good tests, but it isn't easily discerned.
Recently, I did a code review for a colleague and from the start I felt that the code was right. Every method I encountered did nicely what it communicated or it referred to other well named methods and interfaces that did what they advertised. The code review took me just a few hours (for quite some code). I had a high level of trust from the outset because of very descriptive tests, followed by a number of random samples from the production code that further validated the high level of trust I had in the code. I rightfully praised him for his good effort.
Now that I have outlined what increases my trust in a codebase, lets look at an example where the trust I have in the code was shattered. I recently worked with code that had to search for something.
public void SearchForItem(SearchParameter param)
{
// some parameter verification
FindItem(param);
// usage of param.FoundItem
}
private void FindItem(SearchParameter param)
{
// find the item
// update the database
// update property in param object indicating which item was found
}
It starts with the return type of the method SearchForItem, it doesn't return anything. Quite strange for a method that searches for items. Then I couldn't understand why the next FindItem method again didn't return anything. Further down the method, a property of the SearchParameters object that described the found item was used. When I inspected the FindItem method, I discovered that not only did it found the item but it also updated the database (regarding the item that was found) and set the FoundItem property on the SearchParameters object. I think it is fairly obvious why I did not trust any other method in that part of the code from there on out and why updating this code took me quite a bit of time.
That is exactly why trust is so important. If I don't trust code, I cannot rely on the description of the method name to be certain what it does. I need to check that method to be sure what it does. When I encounter methods that do more or something else than they communicate, it further erodes the trust and I spend more time checking what each and every piece of code does.
In a codebase with a high level of trust, I don't need to investigate the implementation of every little (or big) method to be sure that it doesn't do anything else. This allows me to find bugs more easily or pinpoint the location where I need to update functionality because I can rely on the description of all interfaces, classes, methods and variables.
Make sure you write and keep your code trustworthy.