TensorFlow mask definition

Search for a command to run...
An excellent article on how TensorFlow returns results. It caught my eye as I was planning to learn TensorFlow basics. 👀
Phew, that was a lot. I'm always surprised how simple solutions contain so much detail and nuance when I try to explain them. I hope I conveyed the message that A-Frame simplifies code within a module or class by separating the infrastructure compone...
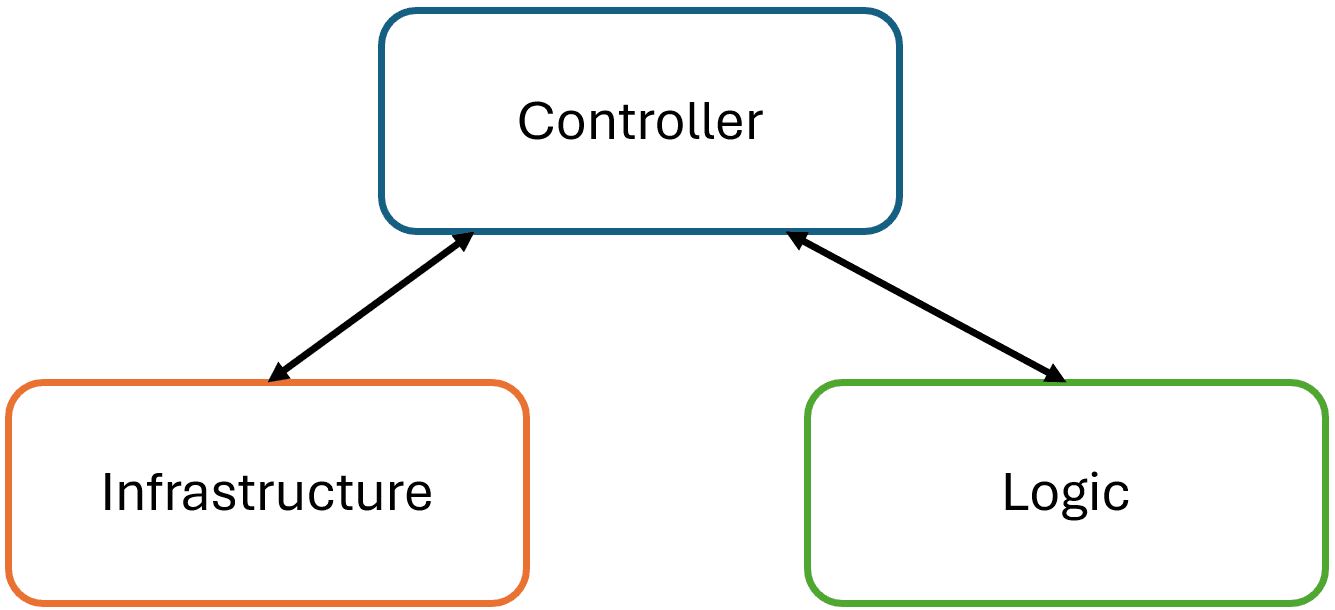
No architecture is complete without an easy way to test the functionality. My recommended strategy is to use two types of tests: unit and integration. As far as test setup goes, there is no clear winner for a test framework. xUnit.NET, NUnit and the ...
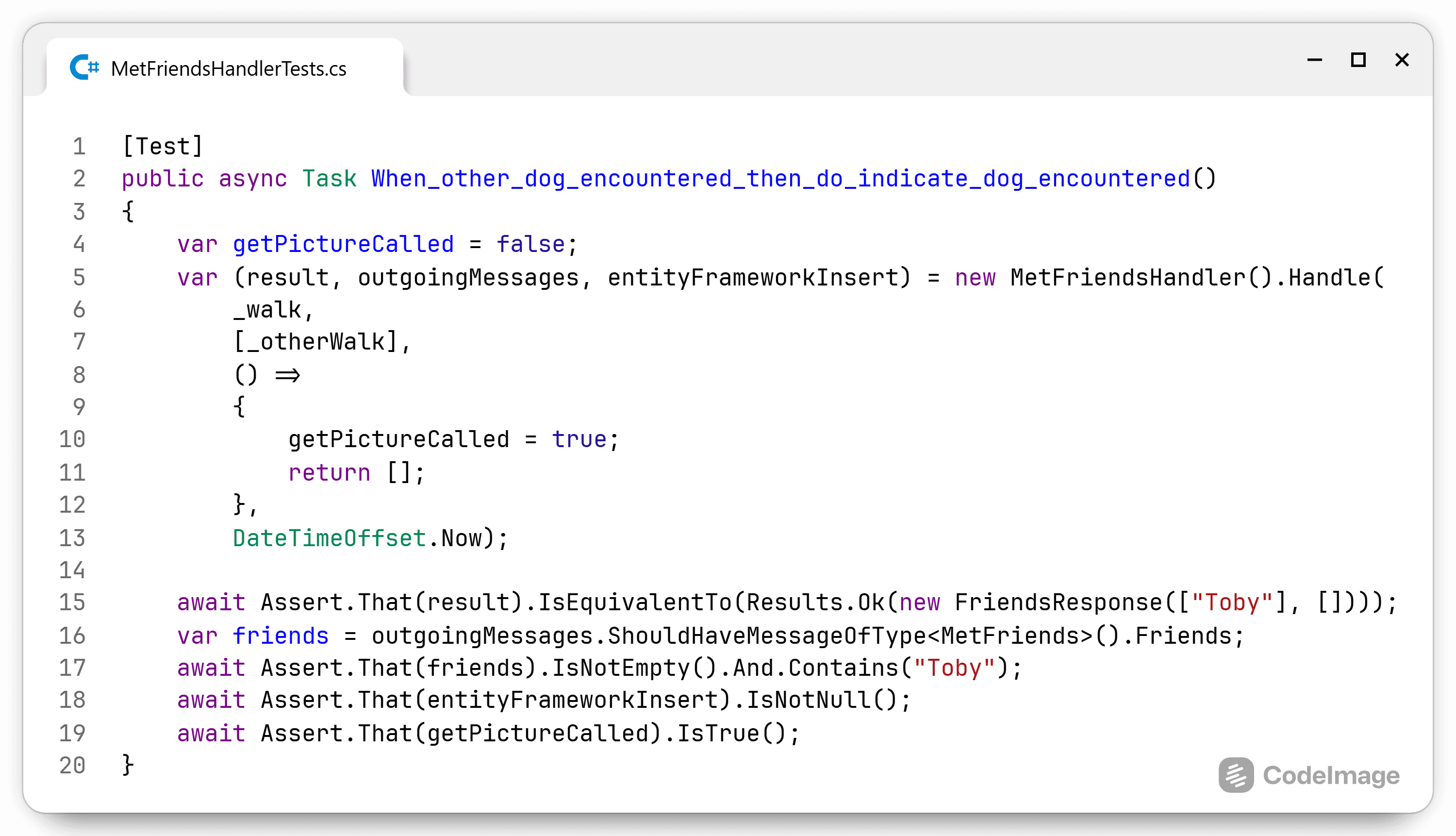
The examples in the previous posts seem really nice for simple scenarios. How do I approach more advanced use cases? The big scenarios are: I need multiple pieces of data from different sources I need to perform an infrastructure call in the middle...
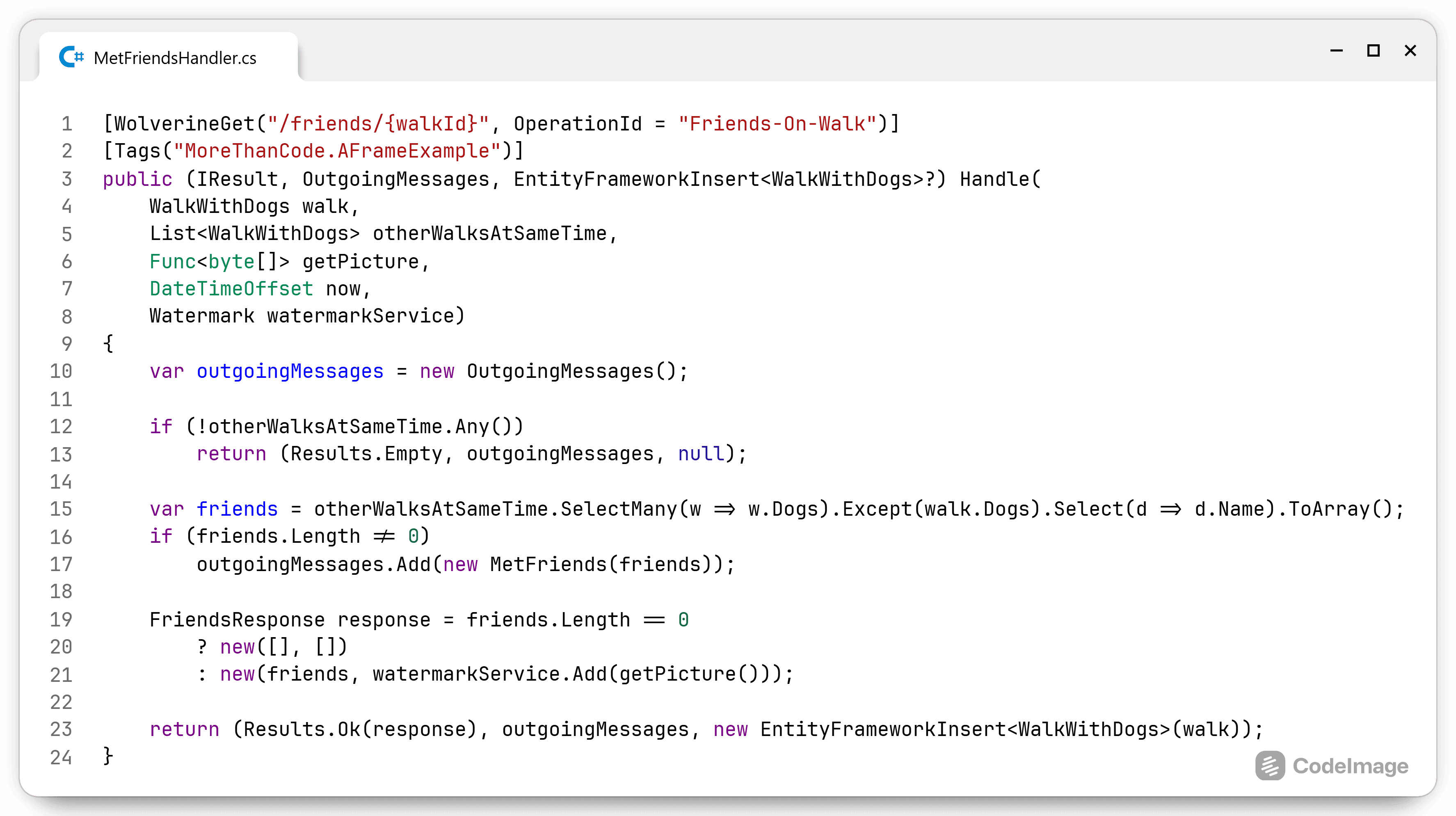
I’ve shown how I write code using the A-Frame architecture without help. Yet I find a library or framework very convenient when using advanced techniques. Wolverine is at its core a messaging framework, but goes well beyond that. It has an in-memory ...
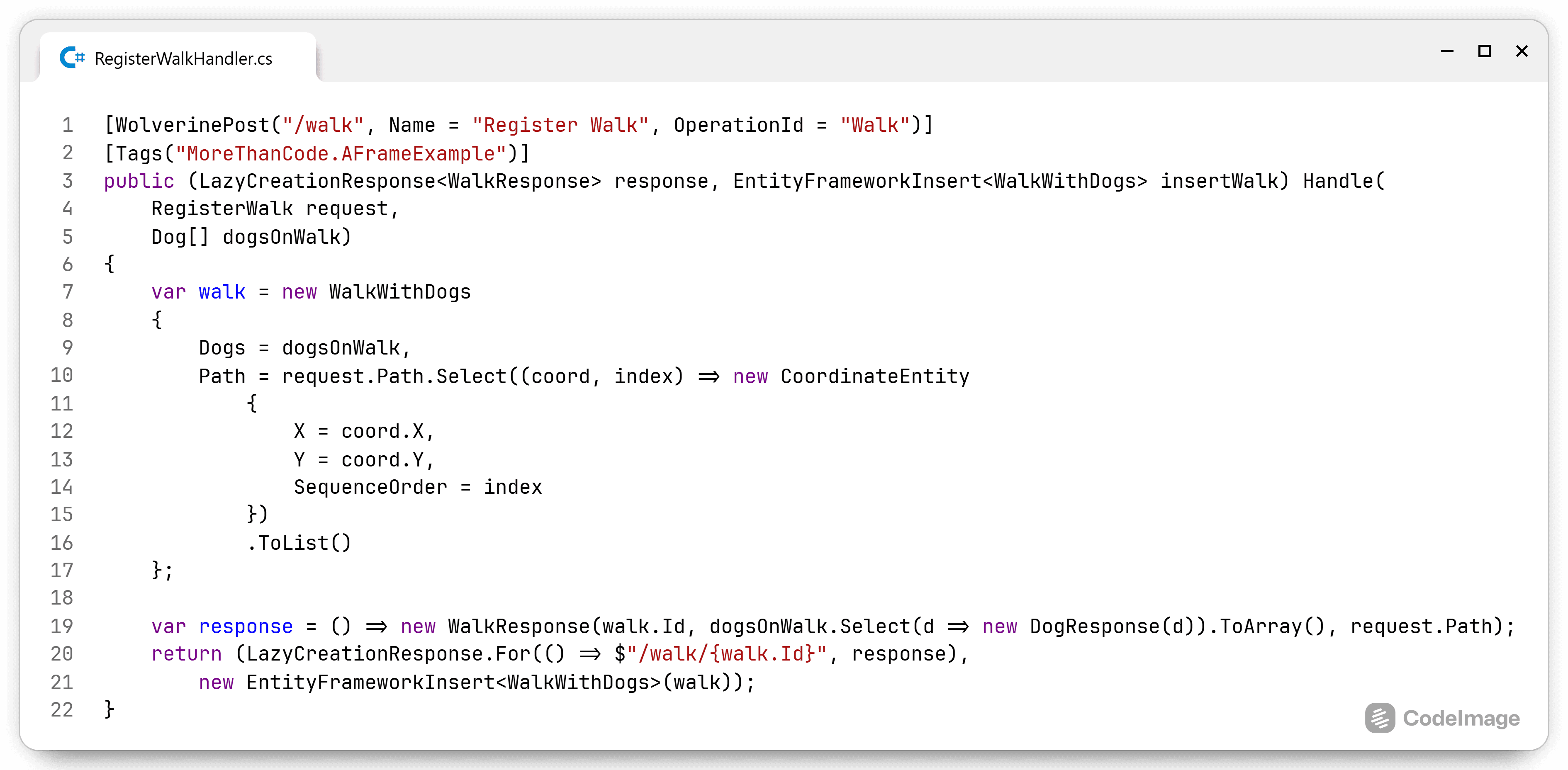
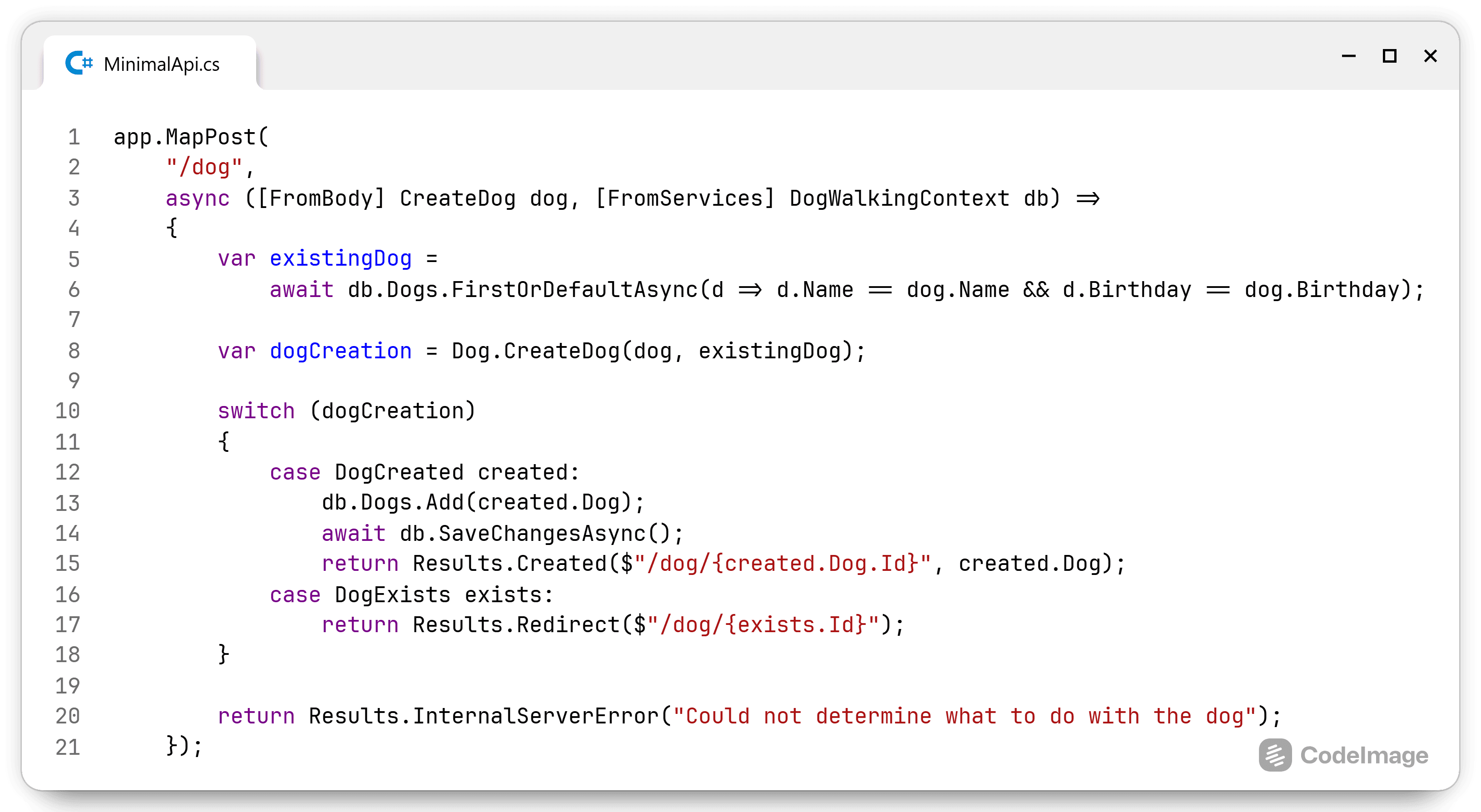
Now the expected structure is clear, let's take a look at the code. I will start with a minimal API implementation to demonstrate that there is no need for a framework to implement this architecture. I do know of a framework that makes A-Frame effort...
A little while ago, I needed to parse a TensorFlow result in a dotnet application. Most of the interpretation of the result was fairly easy as there is a ton of documentation about TensorFlow. Until I had to apply the mask that TensorFlow returns.
Warning: math and complex code ahead!
I needed to block out a part of an image, a face, to make people in photo's unrecognisable. The easy way would be to block out the rectangle that is supplied via the detection_boxes. It would be nice if I could block out just the face instead of a huge square block. So enter detection_masks output.
When TensorFlow returns a result, it's a dictionary of multi-dimensional arrays. One of the dictionary items, detection_masks, is a three dimensional array of floats that specify which part of the detection_boxes contains the actual face. Before I get into this, let me back up a moment and explain what this service returns.
For me, it was quite confusing because the different dictionary items correlate to one another. Let's say that I have a picture that I process and TensorFlow returns 10 recognised objects. The first dictionary item that I need are the detection_scores. The first score is the object with the highest confidence, so TensorFlow is fairly certain that it identified this object. The value will indicate how high the score is, 1 is 100% certain and 0 is 0% certain. In my results, the first few scores were 0.8 or higher and then it suddenly dropped off to less than 0.3. For this example, let's say that the first score is 0.92, this means that TensorFlow is 92% certain about what it found.
If I want to know what the result indicates, I need to check the dictionary item detection_classes for the corresponding item in the list. So the first item in the detection_classes will tell me what the first item in the detection_score identifies. The second item in the classes will tell me what the second item in the scores identifies. And so forth. In the detection_classes array will be numbers that correspond to what the model found. The numbers are specific to the model. So class 1 from this model may mean something completely different from class 1 from somebody else's model. For this example, let's say that the first class is 1, which in this model is a face.
Now that I know that TensorFlow is 92% certain the first result is a face, let's find the box it is located in. The coordinates are located in an array of floats in the dictionary item detection_boxes. The boxes are a little strange as they are grouped together in blocks of four, meaning that positions 0, 1, 2 and 3 contain the coordinates of the box around the first score and class. Array position 4, 5, 6 and 7 contain the box coordinates for the second score and class. Let me clarify further with an example.
Let's focus on the positions of the first result (positions 0 through 3). Each value is a percentage of the width or height of the image. The first two positions (0 and 1) are the minimum positions of y and x. Be careful as the normal positions are reversed! The first value is the minimum y position and the second value is the minimum x position. Then come the maximum y and x positions. Again, watch which value you use, I ended up drawing some weird boxes before I figured it out.
How do I get to the actual x and y coordinates of the image? I multiply the value with the width (for an x point) and the height (for a y point). For this example, let's say that the first 4 values are 0.2, 0.3, 0.5, 0.8 and the image dimensions are 10px wide and 20px high. This would give us two points: (y: 4 = 0.2 x 20 | x: 3 = 0.3 x 10) and (y: 10 =0.5 x 20 | x: 8 = 0.8 x 10).
Whew, that was confusing and I still have the most funky scenario coming up. Let's just pause for a moment, catch our breath and marvel at the wonder that the box around a face can be drawn. Did you get something to drink, a cool glass of water, maybe a 15 year old single malt? Good, then let's continue through the example with the last step: blurring the face.
To find the face, I need the box indicated by TensorFlow. TensorFlow tells me where in this box the face is located. Again, the next part depends on how the model is trained. So your results may vary from mine.
What TensorFlow does, is divide the box up in mini rectangles. For example, if TensorFlow divides the box up in rectangles 16x16 and the box is 32px high and 64px wide then each box will be 2 by 4 pixels in dimensions. Each box will receive it's own score how likely it is that the object, in this case a face, is in the box.

Let's take the above picture as an example: it is the box that TensorFlow identified as my face from a larger picture. In this example, the mask has a granularity of 5x5. Each box will get its own score. For this example, I want to focus on 3 boxes. Box number 1 will receive a score very close to 0, something along the lines of 0.001132... This will tell me TensorFlow does not think my face is in this box. Box number 2 will probably receive a score around 50% (think 0.540887...), which tells me that my face may be in this part of the box. Box number 3 will receive a high score, probably over 90% (think 0.938492...). This means this box will surely contain my face.
The scores can be used to guess the outline of my face and black out my face. Depending on how rigorous I want to be, I can block out just my nose, mouth and eyes or go for my hair and chin too if I set the confidence level lower. But where do I find these numbers?
TensorFlow returns a three-dimensional array of floats called detection_masks. The first dimension of the array refers to the detection_boxes, the second dimension refers to the number of rows the box is divided in and the third dimension contains the actual confidence levels.
Let's apply that to the example. I would have an array with the first dimension length equal to the number of found items in the total picture. The first item in the first dimension refers to the box with my face that has that 92% certainty. The two following dimensions tell me in how many parts the box is divided. With the picture above, this will be a 5 by 5 array. That means that the first array of the second dimension contains an array with the confidence values of the top row of boxes in the picture. This is also how you can calculate how big the boxes are in my 16x16 example earlier. The third dimension then contains all the numbers with the confidence levels (the values of the three boxes I talked about earlier).
Finally, I present you my code to blur the face when I cut out the detection_box from the bigger picture where I pass in the specific detection_mask for that box.
public Image BlurFace(Image image, float[][] mask)
{
var destImage = new Bitmap(image.Width, image.Height, PixelFormat.Format24bppRgb);
using (var graphics = Graphics.FromImage(destImage))
{
graphics.DrawImage(image, 0, 0, image.Width, image.Height);
var yRatio = (float)image.Height / mask.Length;
var xRatio = (float)image.Width / mask[0].Length;
var maskBlockSize = new Size((int)Math.Ceiling(xRatio), (int)Math.Ceiling(yRatio));
var maskBlocks = new List<Rectangle>();
for (var y = 0; y < mask.Length; y++)
{
for (var x = 0; x < mask[0].Length; x++)
{
var shouldMask = mask[y][x] < MaskMaxConfidence;
if (shouldMask)
{
var maskBlock = new Rectangle(new Point((int)Math.Ceiling(x * xRatio), (int)Math.Ceiling(y * yRatio)), maskBlockSize);
maskBlocks.Add(maskBlock);
}
}
}
var brush = new SolidBrush(Color.Black);
graphics.FillRectangles(brush, maskBlocks.ToArray());
}
return destImage;
}
Phew. That was a difficult last part to get my head around. I hope this information helps somebody to better understand how TensorFlow returns results, because I didn't really find any help on what was in the detection_masks arrays. This is very specific and I hope I shed some light in the darkness that is machine learning.