Implementing a KeyedCollection in .NET Core
A coworker pointed out that when performance is important, a custom KeyedCollection is pretty hard to beat. Let's find out if this is true in the new and improved .net core framework.
To make it easy for myself, I'm going to assume that you have installed Visual Studio 2017 and kept it up to date. That way I can just jump into the code and get things going without having to write yet another getting started with .net core blog post. I bet you can find one on your own. :)
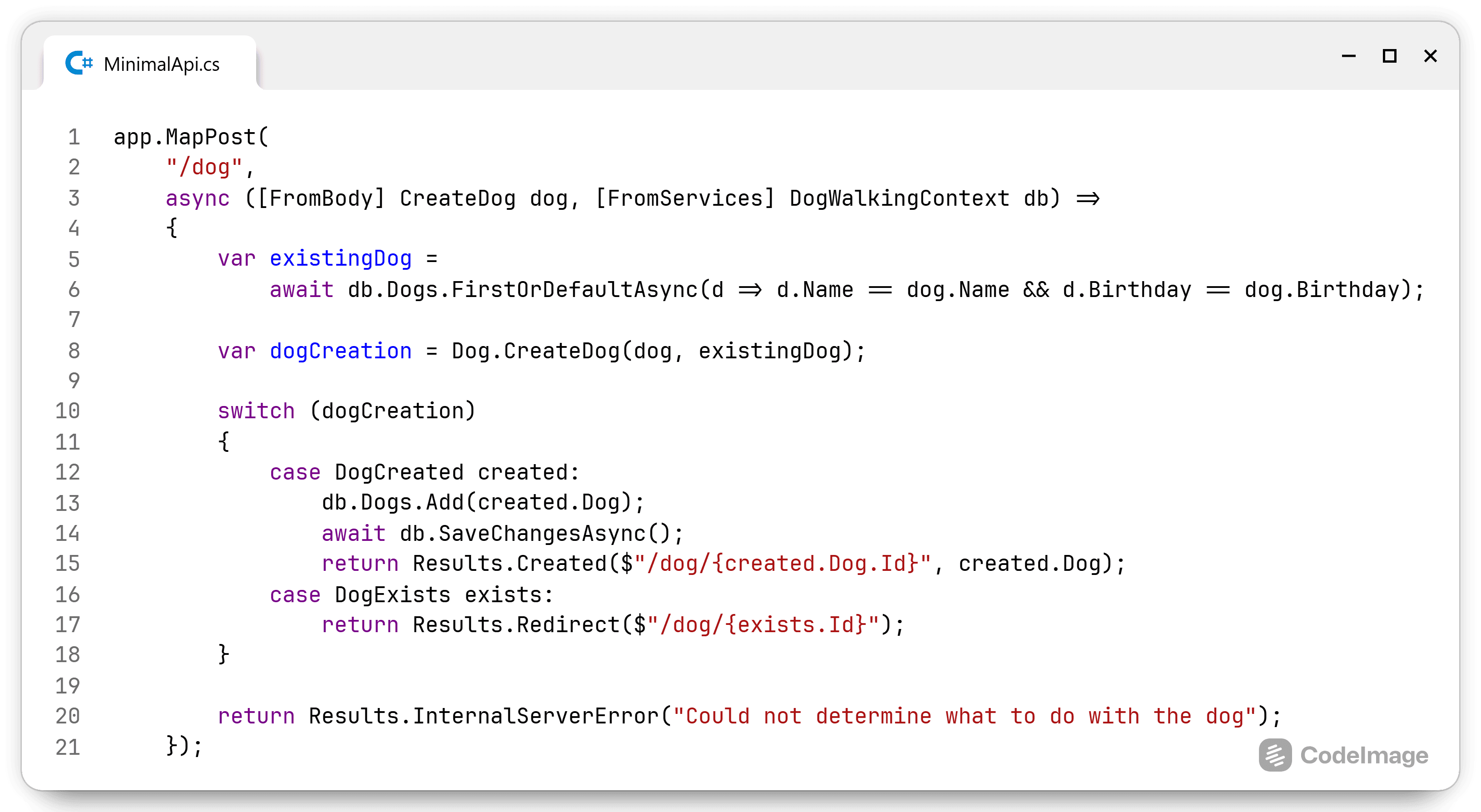
Back to the topic at hand, the KeyedCollection.aspx). This is a mix between a Collection and a Dictionary. A KeyedCollection looks a collection, but items can quickly be accessed trough a key. That's why the signature is a generic that takes in a TKey and a TItem. Internally, the KeyedCollection keeps an IDictionary to store all items. When I inherit from the KeyedCollection<TKey, TItem>, I have to specify wich property from the TItem represents the TKey. Now each time I look up a value, it can happen very fast as it looks up the value by its key.
To do this, I have created a custom KeyedCollection for a Customer item. The Customer is just a value class with 3 properties: a string Name, a DateTimeOffset BecameCustomerOn and an int PriorityLevel. I just needed something easy to work with. (Btw, if you didn't know, DateTimeOffset is the new DateTime.)
public class Customer
{
public Customer(string name)
{
Name = name;
BecameCustomerOn = DateTimeOffset.Now;
PriorityLevel = 2;
}
public string Name { get; set; }
public DateTimeOffset BecameCustomerOn { get; set; }
public int PriorityLevel { get; set; }
}
The code for the CustomerKeyedCollection is even less work:
public class CustomerKeyedCollection : KeyedCollection<string, Customer>
{
protected override string GetKeyForItem(Customer customer) => customer.Name;
}
This is all you need to get started with your own custom KeyedCollection.
The big question is: is it really faster than the build in collection types? Let's not get ahead of ourselves and actually verify this in a semi scientific way: by measuring stuff. Time in this case. I'll start with what appears to be the depressing part: inserting items.
For this purpose, I have created 4 xunit tests (if you hadn't noticed, I'm a fan). In each test, I load 1.000.000 Customer objects into a List<Customer>, Collection<Customer>, Dictionary<string, Customer> and finally a CustomerKeyedCollection. They all follow the same basic pattern, just with CustomerKeyedCollection replaced by the earlier mentioned other IEnumerables.
[Fact]
public void Speedtest_when_adding_a_million_customers_to_CustomerKeyedCollection()
{
var collection = new CustomerKeyedCollection();
for (int i = 0; i < 1_000_000; i++)
{
var customer = new Customer(Guid.NewGuid().ToString());
collection.Add(customer);
}
}
Here are the results of a run, the numbers vary slightly with each run, but the order stays the same each time.

The fastest way to complete the insertions is the List, followed by the Collection with some distance. The Dictionary and KeyedCollection take an almost shared last place. The Dictionary is always about 0,02 seconds faster than the CustomerKeyedCollection.
To me, this is no surprise as the KeyedCollection is basically a wrapper around a Dictionary that specifies the key as a property on the object saved. So, let's move on to the reading part of the tests, in which my coworker claims that the biggest speed bonus is achieved.
The test setup is kind of the same, but now I'm using an xunit feature called Fixtures. A fixture is injected into the constructor and is created only once for a test class. This lets me initialise the million records in memory before running all the tests. There is a link to the source code at the bottom of this article if you want to see how the fixture class looks like (if you want to read more, check my previous blog post). In this fixture, I fill a List, Collection, Dictonary and CustomerKeyedCollection each with a million Customer objects with somewhere (each time on the same random index) a fixed customer object.
The read speed tests again all look the same; in the constructor, I get a reference to the test fixture that contains the data and in each test, I search through the data for the corresponding collection. An example for the List:
[Fact]
public void Read_from_customers_list()
{
var customer = _fixture.CustomerList.First(c => c.Name == _fixture.RandomCustomer.Name);
Assert.NotNull(customer);
}
The Collection looks the same as the List, but the CustomerKeyedCollection and Dictionary are just a little different as they read from a key:
[Fact]
public void Read_from_customers_keyed_collection()
{
var customer = _fixture.CustomerKeyedCollection[_fixture.RandomCustomer.Name];
Assert.NotNull(customer);
}
Now that you know how professional I set up these tests, it's time to look at the results:

Well, this is looking promising. The two fastest are the CustomerKeyedCollection and the Dictionary. The List and Collection are way behind with their searches. Now this is a single search through a million records and to be fair, the List and Collection use Linq which will always be slower than the blazing fast index lookup that a Dictionary supports. I have also seen slower lookups from List and Collection on different runs. I think this is related to where the random customer is located in the lists. The more to the front the random customer is, the faster he will be found as the collections have to look through less customers.
I just have one problem with the granularity of this result: I can't determine if the CustomerKeyedCollection or the Dictionary won this race. So, lets dig a little deeper. I can inject the ITestOutputHelper into the test class and xunit will recognise this and provide an implementation. This interface lets me write to the output console on the right of the test result. I combine this by starting a Stopwatch in the constructor of the test and stop it in the Dispose() method of the IDisposable interface I implement. Check one of my previous articles again for more info on test initialisation and cleanup. Via the ITestOutputHelper I can write the result to the test console.
public ReadSpeedTest(ListInitialisationFixture fixture, ITestOutputHelper output)
{
_fixture = fixture;
_output = output;
_stopwatch = Stopwatch.StartNew();
}
public void Dispose()
{
_stopwatch.Stop();
_output.WriteLine("Total execution time: {0:c}", _stopwatch.Elapsed);
}
A Stopwatch measures the elapsed time a lot more precisely than the result of the test run. Although I think xunit uses the Stopwatch class to measure test runs. Anyway, when I run the tests again, I get the following results:


The Dictionary is about 0,0001 seconds faster than the custom KeyedCollection. The reason they both show up as 0,001 seconds is because that's the closest round that is shown in the unit test run. So, there we have it, the KeyedCollection loses by quite a bit, but both are really fast compared to the List and Collection.
Now, is there no reason to use a KeyedCollection? I think in some very edge cases there is a use case for such a specific class. I have not explored the full range of details the KeyedCollection has to offer. Not by a long shot. It is possible to implement a custom comparison for key values by implementing a custom IEqualityComparer and passing this along to one of the base constructors. This could speed things up if the keys are complex objects. There are also overloads for adding, removing and setting items.
This KeyedCollection isn't something I would use a lot seeing how optimised the Dictionary already is and how easy Linq is combined with a List, Collection or other data source. It could be useful in highly optimised environments where every microsecond counts and I need a lot of key lookups with a highly specialised key. It was nonetheless interesting to explore something a bit more exotic in the .net core framework.
For those who are interested in the code, you can find it all in a repository on my GitHub. If you have any improvements, do send a pull request. I love to learn new things.
P.S. The KeyedCollection is also available in the full .net framework.