While I worked at my previous employer, I build a proof of concept to improve their ability to search. I will rebuild that proof of concept and I'll highlight all the patterns and principles I used to build this code. All code related to this proof of concept can be found in a repository on my Github account.
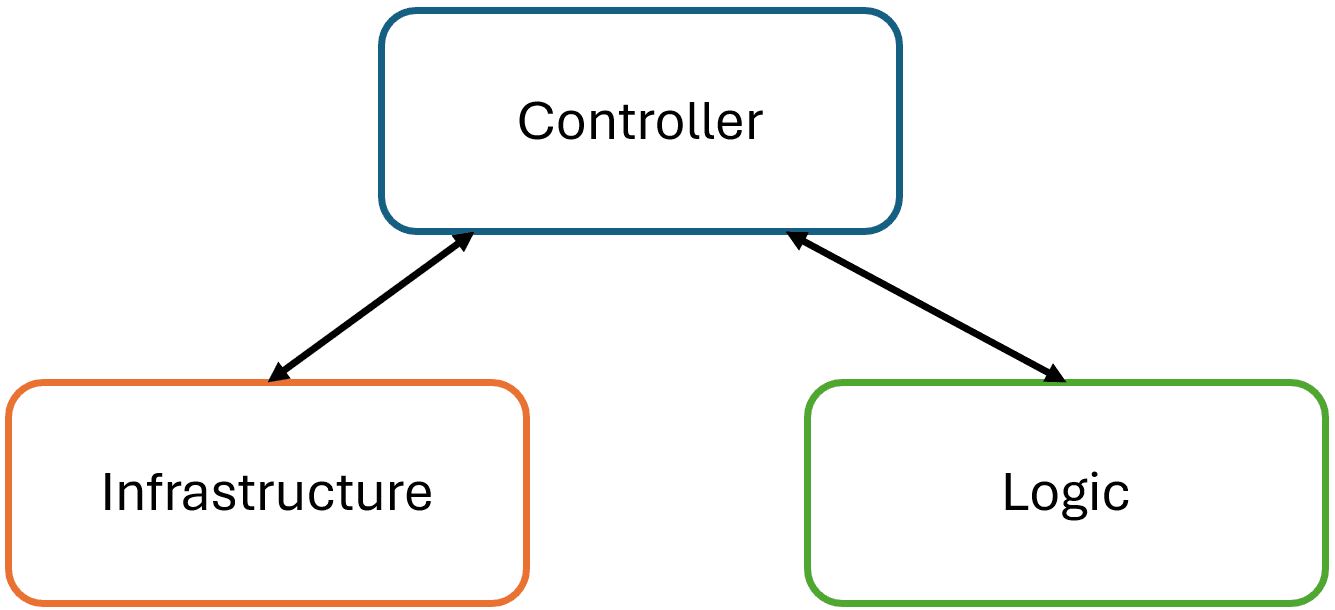
In this fourth instalment, I want to highlight how I divided the solution in different projects.
The Test project contains all the tests that describe use cases. The Test project also has references to all other projects, so this acts both as the consumer of the ISearcher interface and as bootstrapper of the ConfigurableSearcher implementation.
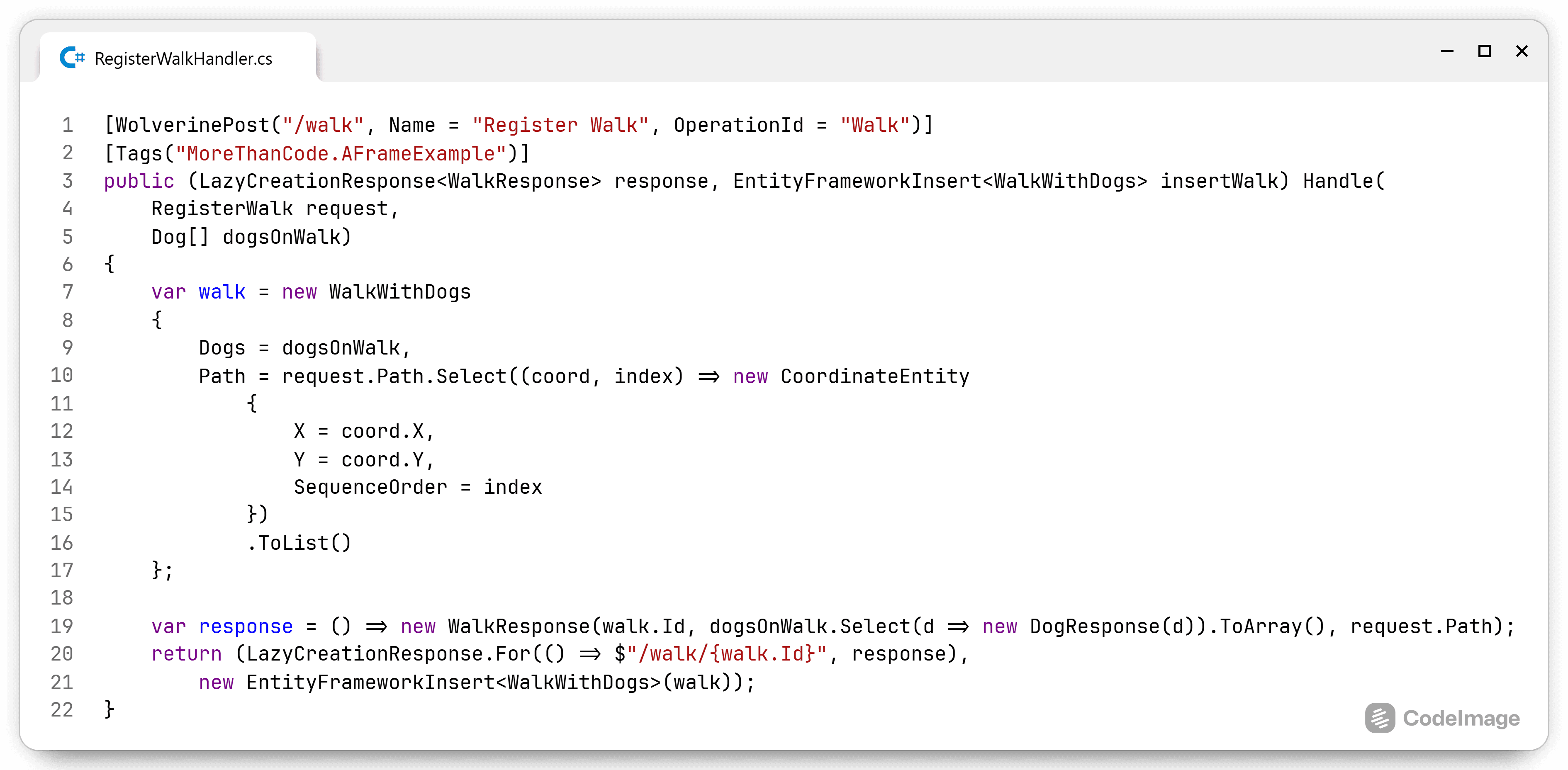
The Core project contains all the relevant classes that resolve around the ISearcher interface, both the return structure and all the subclasses of the SearchQuery object. Core projects should not have any dependencies besides some .NET specific dependencies. I would not want to be tied to a specific library or framework for my search. If this is the case, I suggest factoring this out into another project and putting an interface between the framework/library and the core project. If the third-party dependency should change or doesn't provide something, then it isn't intertwined with (a part) of the software.
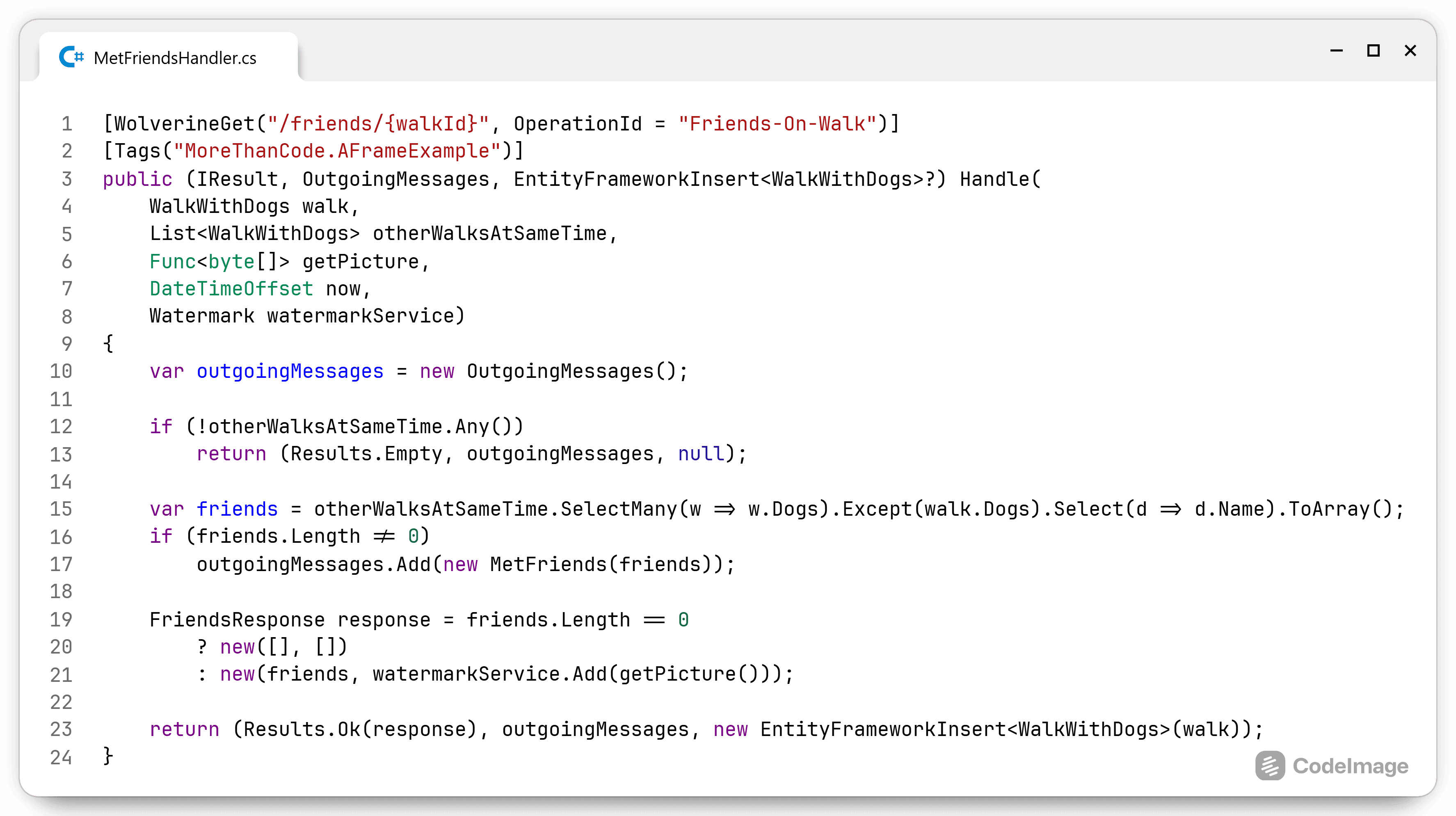
This is the same reason why I split up the DefaultImplementation project and the DataAccess project. The DefaultImplementation project should not know which database it is accessing (if it is a database). When I want to implement the IFilter interface in a different library, say something specific for a certain client, then I don't want to have to add dependencies to the client specific project on SQL libraries, entity framework or maybe even logging frameworks. I just want the interface I'm interested in.
Over the course of many projects, I have seen this a lot. "Oh, I want to implement ISomething interface. Hmmm, red squiggly line because I didn't add log4net to my dependencies." I shouldn't need to add dependencies to any other libraries except the ones I really need.
Splitting these dependencies up makes writing tests a lot easier. This allows me to make a fake implementation of my own IRestaurantRepository (or ILog) interface that I can control easily when writing unit tests. Then add a few integration tests to make sure the repository is fetching the right data in the correct format and I should be good to go.
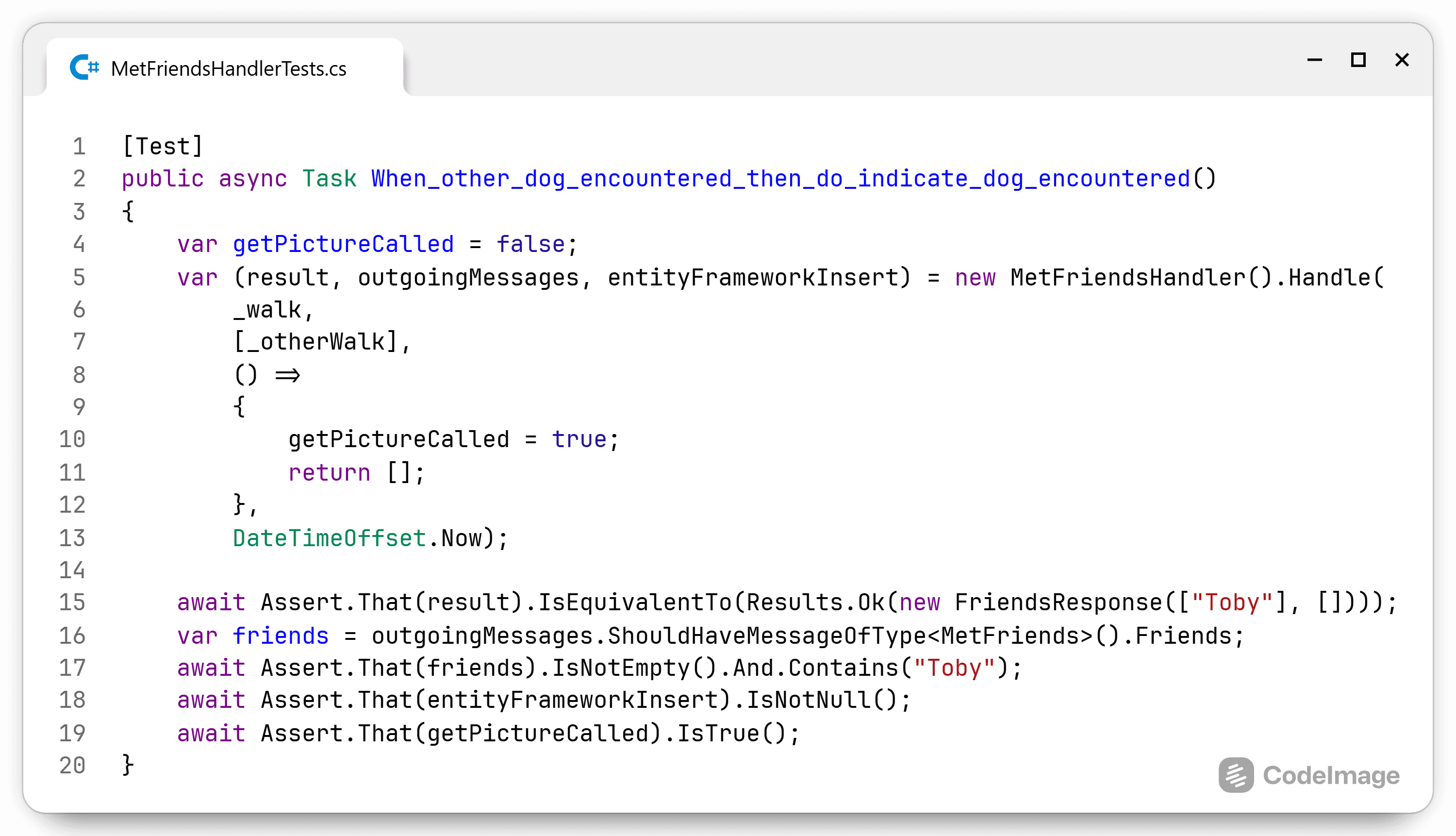
Now I did add a number of internal properties and methods on the read model in the DataAccess project. If I want to create instances of the read model in the Test project, I can do two things. The first change I can make is to publicly expose those internal properties and methods (such as AddSection on the Restaurant class) so everybody can access them. Those members should be hidden behind the interface, but I could access them outside the DataAccess project. The other solution is to grant the Test project access to internally visible members.aspx).
Both solutions don't sit very well with me and I'm not sure what I would do. On one hand, I'm exposing public members that could be private, but are hidden behind an interface. In the other, I'm properly hiding members, but I'm "magically" exposing internals to a test project. I think either way has a smell, so pick with which smell you can live with. For me it's a bit context specific and I change my mind sometimes. In this case I didn't really have a database, so I didn't need to make this choice and I could reference the DataAccess project in my tests.
An additional benefit of separating an interface and its implementation in different projects, is that it makes the project responsible for its communication with external components. The DefaultImplementation project is responsible for indicating what it needs. If it needs additional information, it can make the change in the interface under its control. It doesn't need to go to the DataAccess project to change the interface. The DataAccess project needs to follow the changes indicated by the DefaultImplementation project.
This same logic applies to the Core project as well. Should the use case be extended or changed, then the Core project is responsible for changing the ISeatSearcher interface and thus inform the implementations that they need to change.
For example: the company I used to work with dictated how the time sheet would look like and how I entered my hours. My employer has control over the interface (the website) and I decide how I keep track of the hours worked (the implementation). It would not make sense that my employer would leave me in charge how I would send my time sheet information to them. Before you know it, one employee sends it in an Excel worksheet, one sends it as a PDF and another will make a public API that the employer can access. All the different formats would be a nightmare for the employer. Now, the employer has control over how they get the time sheet data. It is each employee's responsibility to keep track of their time and enter the hours in the website at the appropriate time.
Now that it (hopefully) is clear why I divided the projects along the lines that I did, it's time to wrap up this little series. In the next and last instalment, I will be talking about extending and modifying requests and return values.