While I worked at my previous employer, I build a proof of concept to improve their ability to search. I will rebuild that proof of concept and I'll highlight all the patterns and principles I used to build this code. All code related to this proof of concept can be found in a repository on my Github account.
In this third part, I'm going to discuss the actual search algorithm. The generic implementation of the search algorithm can be found in the DefaultImplementation project.
Let me reiterate before I begin, that this is a substitute problem space as I don't want to describe actual solution of a previous employer. I'm not bound by a non disclosure agreement, but I feel a lot more comfortable not describing internal details of their domain. Thus, examples in this part might be a little strange because they don't reflect the actual domain I've worked with. I do feel that this is the closest I can come to describe the benefits of these patterns.
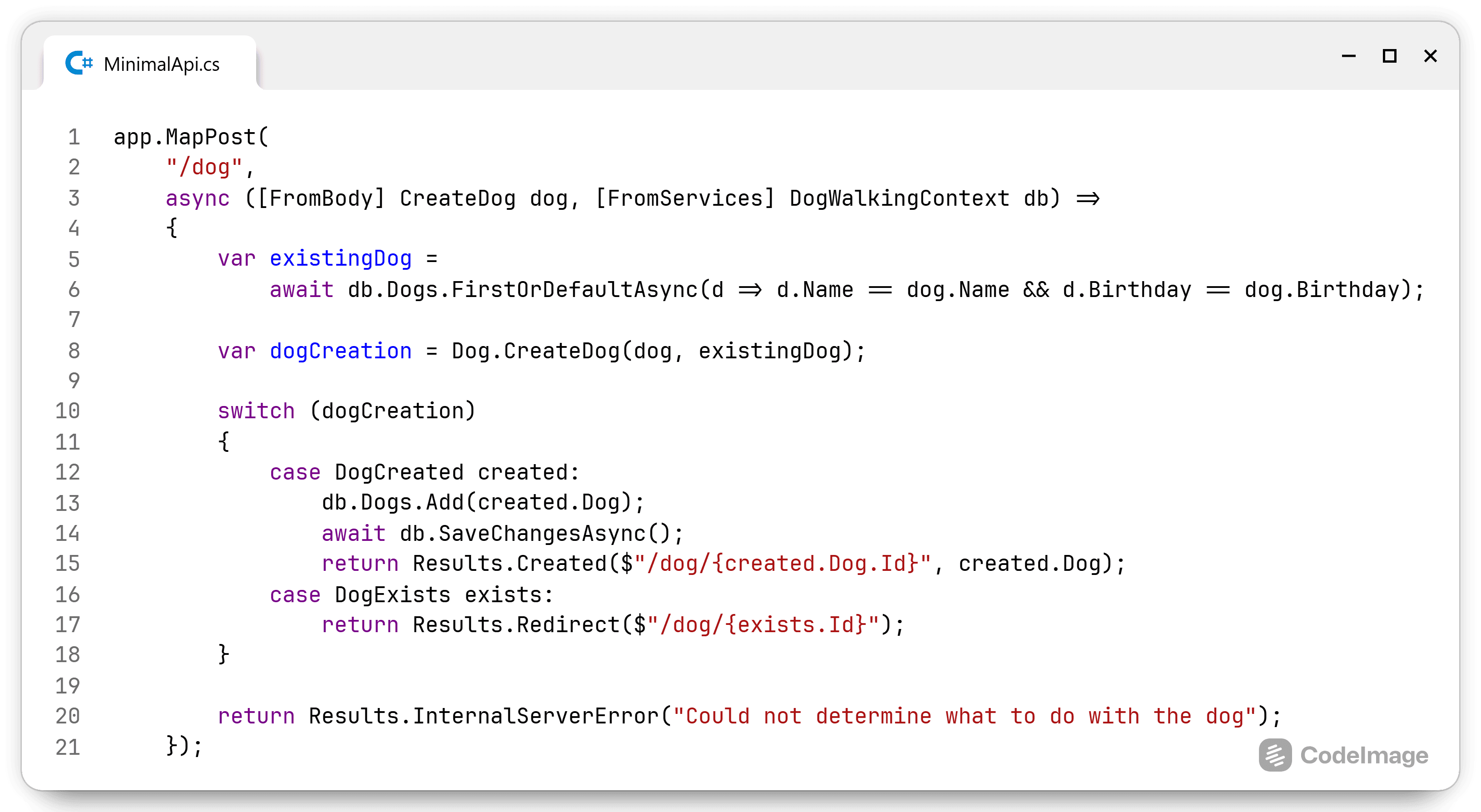
The ConfigurableSeatSearcher takes in 4 interfaces. First there is the IRestaurantRepository that will look for all available restaurants based on the specific SearchQuery. With all restaurants and their data, I get all available seats.
public interface IRestaurantRepository
{
IList<IRestaurant> FindRestaurants(SearchQuery query);
}
When I have the seats, I can run them through all the IFilter instances that were injected. This will remove all unnecessary seats. A seat can access the information of the diner, table, section and even restaurant, this allows for complex scenarios to be resolved quite easily. The SearchQuery object is passed along to the filters as well, because it can contain information that is necessary to make a decision.
public interface IFilter
{
IEnumerable<ISeat> RemoveUnwantedSeats(IEnumerable<ISeat> availalbeSeats);
}
The repository and filters work very closely together to get the relevant seats. I use the repository to access the data store (whether it's a SQL server, a document database or an event store) to get all the information about several or just a specific restaurant. The filters then take a list of all seats and narrow the list down to only the seats that can be selected. This leaves the in-memory representation of the graph intact. For example: when a filter removes seats that are occupied, I can still navigate from the empty seats to their respective table and retrieve information about other chairs and their possible diners.
Next I assign a score to the available seats. The score allows for a first sorting in the next step, but more on that in a bit. The IScoreCalculator is again a simple interface that takes an ISeat and the SearchQuery objects to calculate a score. A lower score means a more preferable seat. For example: A seat at a table with other diners that have the same last name as the diner that is reserving will receive a better score than an empty table or a table with diners that do not have the same last name. So a seat at a table with the diners with the same last name will get score 1, a seat at an empty table will get score 2 and a seat at a table with other diners with different last names will get the score 3.
The score is kept in a custom object SeatWithScore that is only accessible in this searcher. This object keeps a reference to the ISeat object and then keeps a list of a score together with the type of the IScoreCalculator. This provides me with the information of which calculator gave what score to which seat. If this should be logged, prefer using an event that triggers a logging process so this can be a fire and forget kind of scenario. I could also keep the reference to the ISoreCalculator, but I wanted to experiment how well a Type works in this scenario.
public interface IScoreCalculator
{
int CalculateScore(ISeat seat, SearchQuery query);
}
This brings me to the last step of the searching algorithm, sorting the seats. The direction can be influenced by the SortOrder property on the SearchQuery object. This allows to look for badly placed guests by inverting the order, this could be useful for an optimisation process. I haven't found a better way to pass the sort order to the algorithm, so if anybody has improvements, I would love those improvements in the form of pull requests.
The first sorting will always be based on the calculated scores. Then the ISorter will be taken into account. The ISorter interface inherits from the IComparer(Seat).aspx) interface. This takes two ISeat objects and returns an integer. If the return value is greater than 0, the first object is preferred. If the return value is less than 0, the second object is preferred. If the return value is 0, then the objects are considered equal.
For example: tables with less diners get preference because it would spread the diners over the different tables. I can access the number of diners through the table reference on the seat and count the number of occupied seats. Then I subtract the number of occupied seats of the second seat from the number of the first seat. If the first seat is at a table with 3 diners and the second seat is at a table with 2 diners, the calculation is then 2 - 3 = -1. The result is less than 0, so the second seat will be chosen. If the two seats are at the same table, then the result will be 0 and no seat takes preference because they both are at the same table.
This interface is just a nice front for of the IComparer<ISeat> interface. It's not necessary, but it conveys more meaning.
public interface ISorter : IComparer<ISeat> { }
By combining several different implementations of the repository, filters, score calculators and sorters, different seats can be found for different situations. If I want to look for a seat for a diner, I will look for all empty seats in all my restaurant, see at which table family of the diner is located and place them at the same table. If no family can be found, then place the diner at an empty table. If there are no empty tables, then place the diner at a table with other people. Finally, prefer tables with less people so there is more room for everybody at a table.
Then there is a request for another type of lookup, where a seat in a specific restaurant is requested. This time, I don't care that the diner is seated with his family. The basic algorithm stays the same, but now I get all available seats from a specific restaurant (different repository), with a filter that filters out all occupied seats. There is no score calculator this time and then I use the sorter I previously used. I think this makes it very easy to adapt to different requests.
In the next post, I want to focus on how and why I split the code up in different projects.