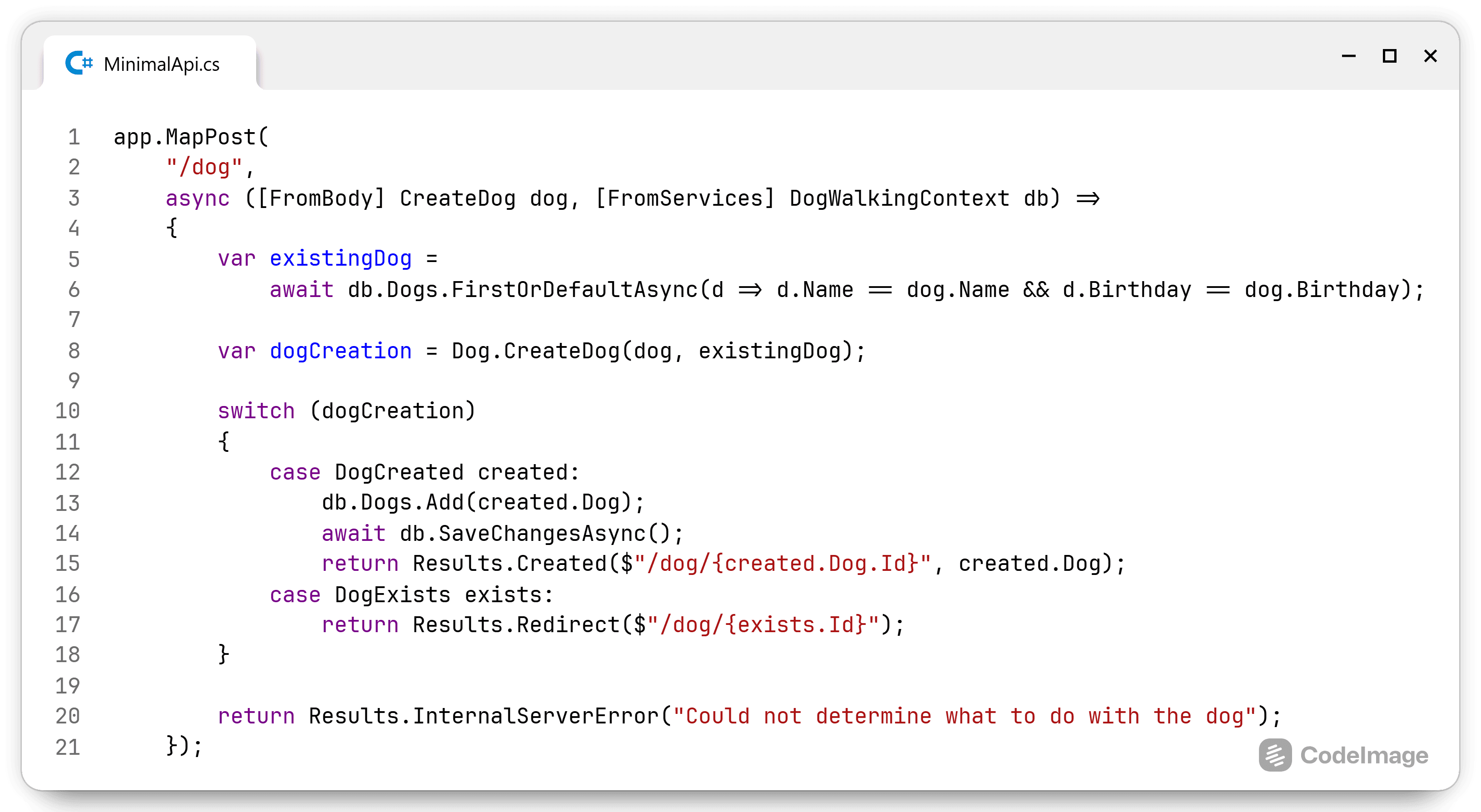
While I worked at my previous employer, I build a proof of concept to improve their ability to search. I will rebuild that proof of concept and I'll highlight all the patterns and principles I used to build this code. All code related to this proof of concept can be found in a repository on my Github account.
In this second part, I want to go into the details of the read model.
The model is something I struggled with for a long time and I don't think I got it completely correct. In this mock example, the model isn't that important, but I do want to take some time to talk about some interesting things I did here. Keep in mind that this is a replacement scenario, so things might get a little strange. With that in mind, let me describe the setup.
There can be multiple restaurants, each restaurant has multiple sections. Each section can have multiple servers (people serving food and drinks). Each section also has multiple tables. Each table has several seats and on each seat there can be one diner (person consuming food and drinks).

Since I only need a read model because it's search functionality, I don't need to implement functionality that will enforce these constraints too tightly. That would be a part of the write model. To make it easy on me, a lot of my objects can navigate not only to underlying objects (restaurant know about sections), but also upwards (sections know to which restaurant they belong to). For example, this is what my Restaurant and Section representations look like:
public interface IRestaurant
{
string Name { get; }
IReadOnlyCollection<ISection> Sections { get; }
}
public interface ISection
{
int Id { get; }
IReadOnlyCollection<ITable> Tables { get; }
IReadOnlyCollection<IServer> Servers { get; }
IRestaurant Restaurant { get; }
}
First thing that is important is that they are interfaces. I use interfaces to promote encapsulation and separation. On the actual implementations, I need methods such as AddSection on the Restaurant class to add a section. This method can be internal to the implementation project, in this case the DataAccess project, and no other class should know about how sections get added to a restaurant. This also ensures that no other source can add additional information. So if this needs to be updated, it needs to be done in the DataAccess project. This in turn ensures that this project is the source of the information. The actual Restaurant class looks like this:
public class Restaurant : IRestaurant
{
private readonly List <Section> _sections = new List<Section>();
public string Name { get; set; }
public IReadOnlyCollection<ISection> Sections => _sections;
internal void AddSection(Section section)
{
section.Restaurant = this;
_sections.Add(section);
}
public override string ToString()
{
return Name;
}
}
In the repository classes, I have a MockDatabase that builds a list of restaurants with sections, tables, seats and a few guests. In a real implementation, I would also add a database model that would populate the read model. In this scenario, the database model would be very accessible (properties with public getters and setter) as that is the database models purpose.
The database model could then be used by Entity Framework or NHybernate to persist the changes. The read model would impose limitations (such as internal AddSomething methods or properties with private setters) so it could not be changed or updated. Internal setter would cause problems with Entity Framework or NHibernate. Besides that, those frameworks would need custom attributes to validate several items (such as primary keys or string length). Adding those attributes to the read model would be a violation of the Single Responsibility Principle.
In production code, it is important to split the read model and database model. The database model is used in multiple places and allows data to be read and updated. The search model on the other hand would be used in the search functionality to limit what can be done with the data. This separation comes from the CQRS design pattern.
Pro-tip: this can also be used for write models. If I want a specific model to use in my writes that can make a reservation, I can have a different IRestaurant interface that has a MakeReservation method that takes in a first and last name of the diner, which then first searches for a seat (using this ISeatSearcher interface) and then it would look up the seat, update it's diner and persist it to the database.
An alternate solution to limit what the search classes can do, is use the IRestaurant (and subsequent) interface in places where only data can be read. Then implement a model in the same project as the IRestaurant. The implementation would look almost identical to the one I build in the DataAccess project, but with public AddSomething methods. This would allow multiple implementations (repositories and tests) to use the same implementation of the read model (one with real data and one with test scenario data) without having to implement it twice.
In my tests, I use the IReservationRepository and it's implementations because there is no real database. All data comes from the MockDatabase class. The implementation of the IRestaurant is now limited to the DataAccess project, the tests should then reference the DataAccess project and be allowed to access the internal properties or implement their version of the IRestaurant interface.
With the general implementation, the tests and repositories would be able to populate the read model themselves based on the scenario they would serve. Another improvement I'm thinking of while I write this. I hope I'm making myself clear enough.
What I want to emphasise is that I use interfaces (IRestaurant, ISection, etc.) to describe the model. The interfaces expose what data can be accessed through methods and properties, while they hide the methods and setters that can be used to modify the data in the model.
Stay tuned for the next instalment where I will describe the search algorithm and how I make it extendable.