Different testing approaches

A while ago I attended a lecture of a programmer who explained the differences between the London and Detroit school
(also called Chicago school) of test driven design. I found his explanation kind of pointless.
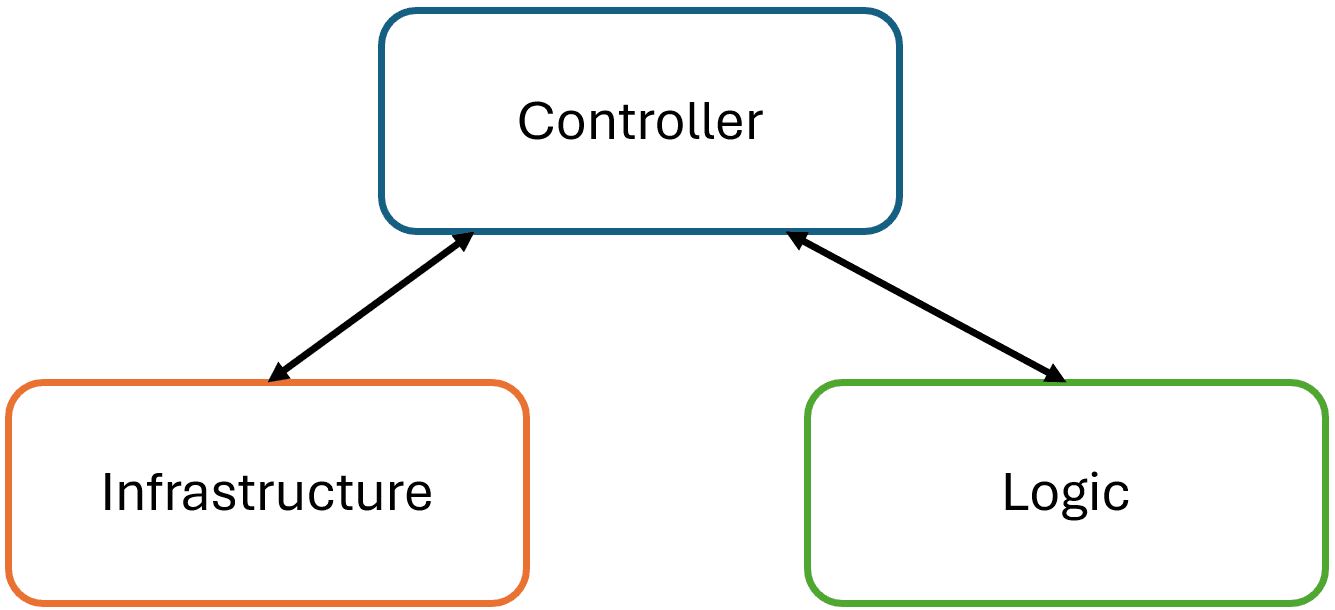
The London school focuses on mock driven testing: dummy/stub/spy/mock out all the dependencies and injections. It focuses on interaction with other components. The Detroit school concentrates on the state of the system, which allows me to verify that the system correctly updates the state of the application. Source.
public class MyClass
{
public MyClass(IRepository repository, ICalculator calculator)
{
// save repository and calculator in fields
}
public void DoSomething(int id, int x, int y)
{
// update text in the database
var sum = _calculator.Sum(x, y);
_repository.Update(id, sum);
}
}
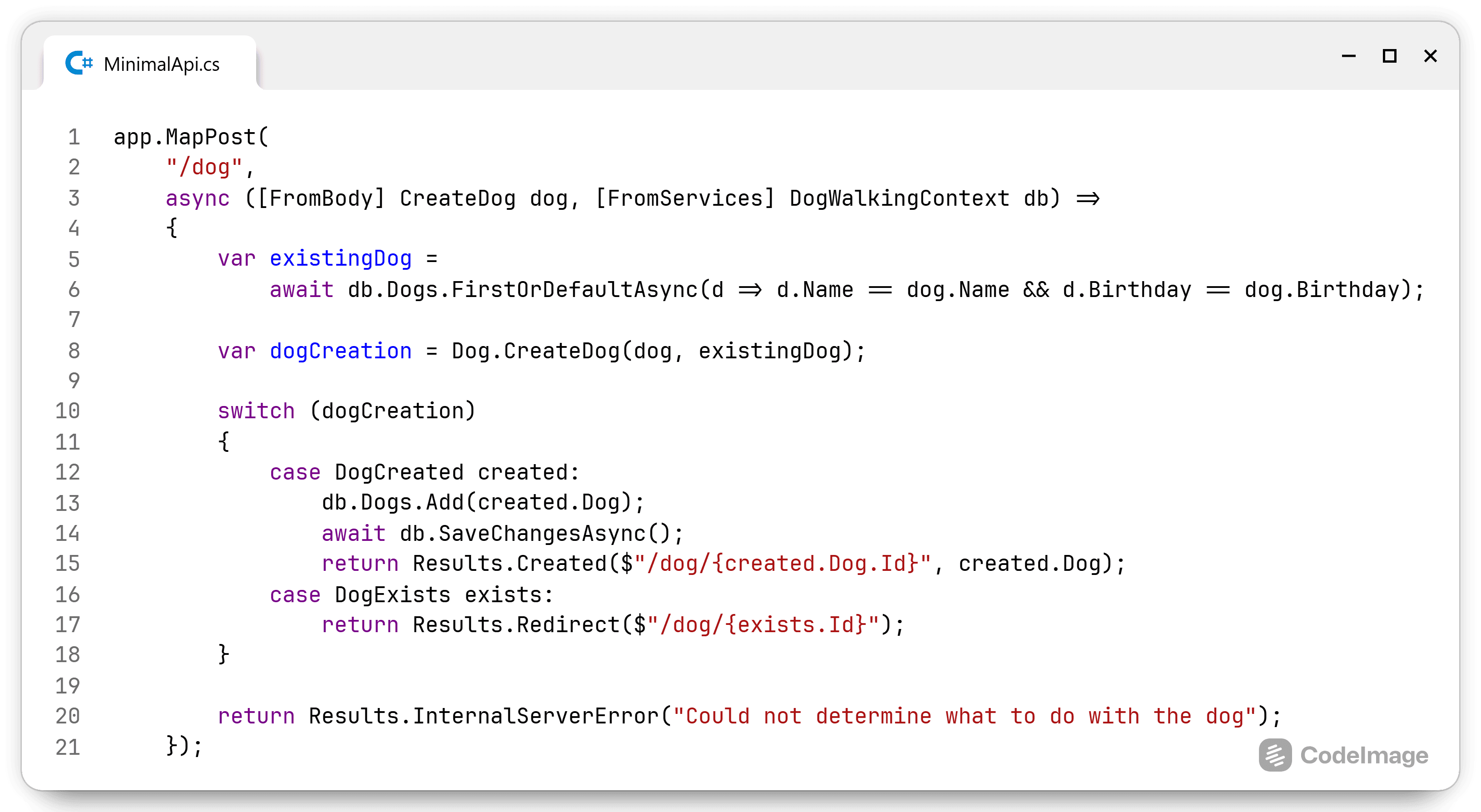
public class MyClassLondonTests
{
[Test]
public void DoSomethingTest()
{
var mockRepo = new Mock<IRepository>();
var mockCalc = new Mock<ICalculator>().Setup(x => x.Sum(2, 3)).Returns(5);
new MyClass(mockRepo.Object, mockCalc.Object).DoSomething(1, 2, 3);
mockRepo.Verify(x => x.Update(1, 5), Times.Once);
mockCalc.Verify(x => x.Sum(2, 3), Times.Once);
}
}
public class MyClassDetroitTests
{
[Test]
public void DoSomethingTest()
{
// made a fake in memory repository implementing the IRepository interface
var fakeRepo = new InMemoryRepository();
// my own calculator
var calc = new Calculator();
new MyClass(fakeRepo, calc).DoSomething(1, 2, 3);
Assert.AreEqual(5, fakeRepo.Calculation.First(x => x.Id == 1).Value);
}
}
This example is what I understand the London and Detroit schools represent. And I think it's counterproductive to say one is better than the other. I think we should throw the schools out the window.
When I build a system, I don't care that my system calls the Update function or the Sum function, in what order and how many times. I want to know that my use case does what it needs to do. In this case, and I think in most cases, checking my in-memory repository FakeRepository does that very easily.
The London school would just slow me down with unnecessary setup and verifying that I called all the correct functions with the correct inputs. It has an additional downside that is not to be underestimated: I want to be able to easily refactor my code. When I move the summation logic into MyClass, I would need to update a lot of the London school test setup, while with the Detroit setup, I would just need to remove the creation of the Calculator and injection into the MyClass constructor.
The Detroit school has the additional advantage that I use the Calculator class, I test that this class works in this use-case scenario. While there are programmers who like a unit test to just test the code in the MyClass and use an integration test to verify that the Calculator class works with the MyClass code, I find that a too fine-grained approach to testing.
While I sometimes write tests to verify specific parts of the code, I remove those later when the unit test, which tests the whole scenario, covers all the code in this scenario. In those small tests, I can make private functions public while I test them. When they work how I like, I make them private again and remove the temporary test.
Just to be clear, a scenario is a specific path through the code. So I can have a scenario "save sum to database" and another "database unavailable" to verify that the code keeps working even if something goes wrong.
The previous parts of this post described that I generally dislike using mocks and I advocate for using all the real parts. But that isn't always convenient for tests. For example, getting a database in the correct state can be a time-consuming part of testing or simulating that a web-service call failure is handled correctly. For those parts, creating a mock/stub/fake/etc can be very time preserving and easy to set-up.
My general rule is: use all code that can run in-memory directly (think my own code, colleagues code, libraries that are used, etc), while code that requires access to external resources (think database, the internet, web-services, operating system information or hard drive access) should be replaced with a mock or a fake. I verify the result against whatever is most convenient.
Recently, I created mock-ups of HTML I wanted to generate, then generated the HTML using a fake data source, but keeping all the code I wrote and the library to generate the HTML from a template. Finally I compared the output with my mock-up. Afterwards, I refactored a lot of the internals of the code to be more efficient, I only needed to edit the test once or twice because I updated either the constructor or the signature of the method.
In this recent example I used both techniques. That's the point I'm trying to make. I don't care if I use some school of testing, I care about working code that is easy to understand. It's not London or Detroit style of test driven design, both techniques are valuable. When calculating or generating things, London style value checking works very well. Detroit style is great for checking that external resources are called with the correct parameters.
So forget the terms that divide us and lets find joy in creating working software with all the tools at our disposal.
P.S. I'm opening up the comment section as an experiment. Let's see if somebody has anything to say.