Now that I have time information about my workdays, the next step is to generate the invoice. There I face another problem. I want to generate a PDF, but I need an easy format to test against. Let me first take inventory of what I have:
- I have an interface
IDocumentGeneratorthat takes the workdays information - I found the DinkToPdf library that converts HTML to PDF
I learned that when I generate the PDF with DinkToPdf, the PDF has metadata included such as the date and time the PDF was created. So, this foils my plan to compare the created byte arrays. It's a good thing that I have smart friends that remind me of the decorator pattern and pointed out that HTML is a lot easier to check.
I use a HTML templating engine to generate the HTML that represents an invoice. I found Fluid to be the most versatile library to generate the HTML I need.
To create the PDF, all I have to do is create a class that takes the HTML document generator, gets its output and let DinkToPdf do its work.
public interface IDocumentGenerator
{
(string extension, byte[] document) Generate(Invoice invoice, Customer customer, BillableItem[] billableItems);
}
public class FluidHtmlDocumentGenerator : IDocumentGenerator
{
public (string extension, byte[] document) Generate(Invoice invoice, Customer customer, BillableItem[] items)
{
using (var htmlStream = Assembly.GetExecutingAssembly().GetManifestResourceStream(TemplateLocation))
using (var htmlReader = new StreamReader(htmlStream))
{
var htmlTemplate = htmlReader.ReadToEnd();
FluidTemplate.TryParse(htmlTemplate, out var template);
var invoiceDocument = GenerateHtml(customer, items, invoice, template);
return ("html", invoiceDocument);
}
}
}
public class DinkToPdfDocumentGenerator : IDocumentGenerator
{
public DinkToPdfDocumentGenerator(IDocumentGenerator htmlGenerator)
{
_htmlGenerator = htmlGenerator;
}
public (string extension, byte[] document) Generate(Invoice invoice, Customer customer, BillableItem[] billableItems)
{
_htmlGenerator.Generate(invoice, customer, billableItems);
// use DinkToPdf to generate PDF
}
}
When testing the code, I just use the FluidHtmlDocumentGenerator, convert the byte array into text and compare that to the output I expect. I have one test that generates a PDF so I can check that the DinkToPdfDocumentGenerator generates the correct output. All I do there is compare the length of the array returned. I can change the test slightly so it writes the output to a file. This allows me to see that I generate a PDF that looks like the rendered HTML. This is a manual process since I haven't found a way to automate this. Which is just a small inconvenience as I verify that my layout is correct with the HTML tests.
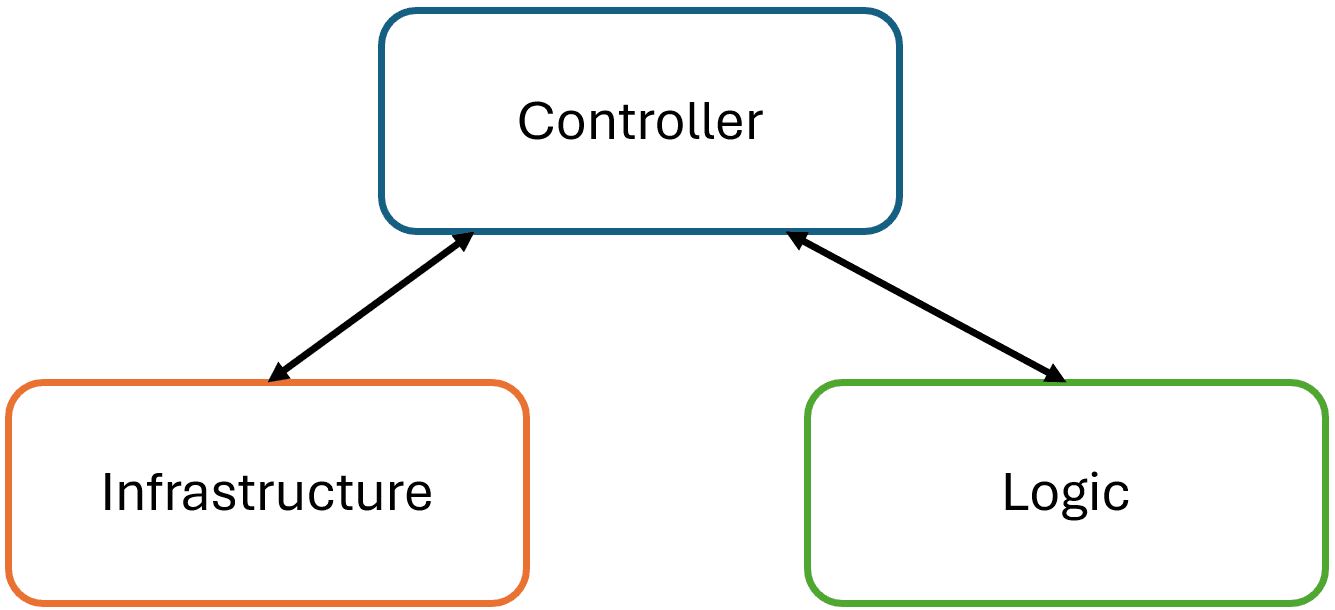
Clean Architecture talks about being independent of libraries. Hiding these libraries behind interfaces allows me to implement other classes with different libraries. That is how I can easily change HTML or PDF generation libraries without my InvoiceGenerator needing any change at all. It's a very flexible and extendable structure.
For example, in most of my tests, my setup of my document generator looks like this: new FluidHtmlDocumentGenerator(). In my actual production code, this changes to: new DinkToPdfDocumentGenerator(new FluidHtmlDocumentGenerator()).
The next infrastructure part is the customer repository, which I will write about next week.